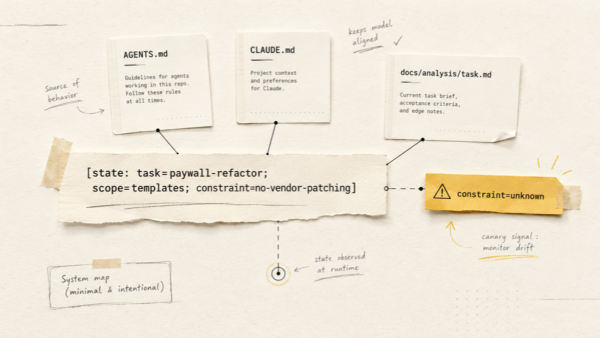
TL;DR
- Цінність AI-щоденника з’являється не в день встановлення, а через місяць, коли записи починають складатися в патерни: сон, стрес, тренування, настрій.
- Агент не «пам’ятає весь vault» автоматично: чесна місячна рефлексія вимагає явно зібрати контекст із файлів, і я показую, як саме.
- Знайдені зв’язки — це гіпотези для спостереження і питання до фахівця, а не діагнози.
У перший вечір після встановлення я кілька разів відкрив папку зі щоденником, щоб переконатися, що файл справді з’явився. Наступного дня перевірив commit. Через тиждень я помітив, що вже не відкриваю папку після кожного запису. А ще через місяць не міг згадати, коли останній раз перевіряв логи вручну. Це був хороший знак: інструмент зник з уваги й лишив тільки звичку.
У першій статті я розповів, як старий ігровий ноутбук став домашнім AI-сервером, у другій ми зібрали систему з нуля. Ця стаття про те, що відбувається далі, коли захват від «воно працює!» минає, а вечірнє нагадування о 21:00 продовжує приходити: про щоденну експлуатацію і про аналіз щоденника з AI, коли записів накопичилося достатньо.
Частина 3 з 3: експлуатація, рефлексія і вартість
Що змінюється після першого місяця
Перший тиждень ви граєтеся із системою: шлете голосові, дивитеся, як росте vault, показуєте боту скриншоти. До третього тижня новизна вивітрюється, і залишається голий механізм звички: вібрація о 21:00, сорок секунд диктовки, підтвердження, і все. У цей момент головною якістю системи виявляється не інтелект моделі, а відсутність тертя. Якби мені доводилося відкривати застосунок і заповнювати форму, я б уже кинув.
Десь після першого місяця я вперше почав задавати щоденнику питання, а не просто складати в нього записи. Не «як я сьогодні» — це я й так знаю, — а «чому вже другий тиждень поспіль до четверга я вичавлений». У одного дня немає відповіді на це питання. У тридцяти — є.
Покажу на складеному прикладі з моєї практики: деталі змінено, щоб не публікувати реальні записи. Три ночі поспіль із переривчастим сном: середа, четвер, п’ятниця. Окремо кожна ніч виглядала випадковістю: спека, пізній серіал, просто не спалося. А в суботу тренування несподівано далося важче, ніж зазвичай. У моменті це виглядало як «поганий день у залі». У щоденнику накопичений недосип став робочою гіпотезою, яку можна перевірити за наступними тижнями, а не готовим поясненням причини.
Окремо мене тоді вразив інший запис того ж тижня. Я продиктував: «стресу не відчуваю, але все бісить». Система не стала записувати високий стрес, бо якорі шкал (ми визначили їх у другій статті) розрізняють ці стани, і в рефлексії з’явилося формулювання, яке я відтоді запам’ятав: недосип з’їдає емоційний буфер. Стрес низький, дратівливість висока, і це різні метрики з різними причинами. Жоден health-застосунок із формою «оцініть стрес від 1 до 10» цієї різниці мені б не показав.
Щоденний workflow без ідеальних даних
Реалістична картина мого дня зі щоденником:
- зранку після залу: скриншот тренування з Hevy (або будь-якого іншого трекера, якщо ви використовуєте інший стек);
- удень: нічого, система мовчить;
- увечері о 21:00: нагадування, голосова нотатка на 40–60 секунд, іноді самарі калорій із YAZIO чи аналогічного застосунку;
- після нотатки: одне коротке уточнення від бота, якщо я забув обов’язкове.
Останній пункт важливіший, ніж здається. Якщо я не назвав вагу, бот спитає рівно одне: «Вагу не озвучив. Зважувався сьогодні?» Не анкету, не список із п’яти пропущених полів, одне питання про найважливіше. Якщо я не відповів, поле залишиться порожнім із позначкою needs_review, і це правильно: порожнє значення чесніше за вигадане. Коли через місяць я будую графік ваги, я хочу бачити діри в даних, а не нулі, які модель ввічливо підставила.
І не намагайтеся диктувати ідеально. Моя вечірня нотатка — це потік свідомості: про сон, про роботу, про те, що кур’єр не довіз замовлення і довелося йти півгодини пішки. До речі, ця нотатка перетворилася на улюблений приклад того, навіщо щоденнику вільний текст: замість скарги в записі залишився рефреймінг «зате кроки закрив і бабусі по дорозі подзвонив». Метрики цього б не вловили. Щоденник, який зберігає лише цифри, втрачає половину життя.
Як виправляти помилки розпізнавання
Перший словник з’явився після того, як система третій тиждень поспіль перетворювала YAZIO на «язіо», а румунську тягу — на що завгодно, крім румунської тяги. Локальний faster-whisper помиляється систематично: одні й ті самі імена, вправи й терміни — однаково неправильно. Практичний спосіб виправлення повторюваних помилок — словник notes/known-asr-errors.md:
# Відомі помилки розпізнавання
| Почуто | Канонічний термін | Контекст | Статус |
|---|---|---|---|
| румунська тяга / "румунський тяг" | румунська тяга | тренування | verified |
| "язі" / "язіо" | YAZIO | харчування | verified |
| "хеві" / "хеві" | Hevy | тренування | verified |
(Приклади синтетичні, ваш словник наповниться власними помилками за перші два тижні.)
Правила, які відрізняють корисний словник від небезпечного:
- у словник потрапляють лише виправлення, які ви підтвердили самі;
- заміна застосовується за контекстом, не глобально: одне й те саме «почуте» слово в розмові про тренування і про людей може означати різне;
- за низької впевненості skill ставить уточнювальне питання, а не мовчки виправляє;
- сирий transcript залишається недоторканим: виправлення живе в нормалізованій зведенні, і в Git-історії видно, що коли змінилося.
На моїй мові словник повторюваних помилок дав більше практичної користі, ніж проста заміна моделі на більшу. Це не універсальний benchmark: порівняйте варіанти на власному наборі коротких записів і рахуйте не лише accuracy, а й latency.
Скриншоти тренувань: довіряй, але перевіряй
Окремий vision-шар (у мене це OpenAI API, до якого я звертаюся за бажанням) видобуває зі скриншота Hevy вправи, підходи, ваги й тривалість. Звучить як магія, працює як стажист: іноді напрочуд толковий, іноді той самий, хто впевнено переписав 60 як 80 і пішов додому. Цифри з екрана — найслабше місце OCR: переплутати вагу, втратити десятковий знак, злити два підходи в один.
Тому правила жорсткі:
- оригінал скриншота завжди зберігається в
attachments/поруч із записом; - видобуті дані отримують
source: ocrіneeds_review: true; - підтверджую я їх одним словом у Telegram, і лише після цього статус змінюється на
verified; - якщо в сервісу є офіційний структурований експорт, зазвичай варто віддати перевагу йому, а не скриншоту, і окремо перевірити повноту полів.
Фото документів: максимум акуратності, мінімум інтерпретації
Найчутливіша категорія: фото медичних документів і аналізів. Тут система робить навмисно мало: розпізнає значення, зберігає оригінал, позначає все needs_review і зупиняється. Жодних трактувань «цей показник підвищений»: без референсних діапазонів, одиниць вимірювання й контексту це ворожіння, а з ними — робота лікаря.
Навіщо тоді взагалі зберігати аналізи в щоденнику?
Щоб на прийомі у фахівця відкрити хронологію: ось значення за пів року, ось мій сон і тренування за той самий період, ось мої питання. Щоденник готує матеріал для розмови з лікарем, а не замінює його. Перед фотографуванням приберіть із кадру персональні ідентифікатори і пам’ятайте про EXIF-метадані.
Тижнева зведення: шар стиснення
Тридцять щоденних записів можна механічно передати моделі з великим контекстом, але це дорого, шумно і ускладнює перевірку джерел. Тому між daily і monthly є проміжний шар: тижнева зведення, яку reflection skill будує із семи денних файлів.
Гарна тижнева зведення зобов’язана:
- рахувати середні лише за заповненими значеннями і показувати знаменник:
сон: дані за 5/7 днів; - не підставляти нулі замість пропусків;
- перелічувати повторювані патерни, а не переказувати кожен день;
- посилатися на конкретні daily-записи як на джерела;
- пропонувати питання для спостереження, не висновки.
Знаменник — найбільш недооцінене поле. «Середній сон 7,2 години» за двома заповненими днями із семи — це не статистика, це випадковість із упевненим обличчям.
Тижневе зведення стало для мене першим моментом, коли щоденник заговорив не голосом окремого дня. Поганий вівторок перестав бути центром світу й виявився однією точкою серед семи. Іноді це підтверджувало відчуття важкого тижня, а іноді показувало протилежне: три дні були нормальними, просто п’ятниця запам’яталася голосніше за решту.
Місячна рефлексія: аналіз щоденника з AI без вигаданого RAG
Тепер про головне розчарування, яке потрібно пережити заздалегідь: агент не пам’ятає ваш vault. Я спеціально перевірив це якось: попросив модель переказати останні кілька тижнів без явної збірки контексту. Відповідь виглядала переконливо — зв’язна, з конкретними деталями й висновками. Половини згаданих подій у щоденнику просто не існувало. Persistent memory Hermes і пошук за сесіями — це не індекс по Markdown-файлах. Якщо просто спитати «проаналізуй мій місяць», модель відповість на основі того, що випадково залишилося в її пам’яті розмов, і це виглядатиме переконливо й буде сміттям.
Чесна місячна рефлексія — це явне збирання контексту. Три робочі режими по наростанню:
Простий: попросити reflection skill прочитати файли за діапазон дат. Працює, але на місяць записів піде багато викликів file tools і токенів.
Рекомендований: helper-скрипт build-reflection-context.sh запускає детерміновану підготовку контексту до всякого AI: збирає daily/2026/06/*.md, парсить YAML, рахує покриття метрик, складає компактні зведення в один тимчасовий файл reflection-context-2026-06.md, і вже цей єдиний артефакт аналізує модель.
Масштабований: місячна рефлексія читає 4–5 тижневих зведень плюс агреговані метрики, і лише для перевірки конкретних гіпотез відкриває окремі daily-файли.
Залізне правило для всіх трьох режимів: посилання на джерело допустиме лише на файл, який реально потрапив у контекст. Якщо в рефлексії написано «див. запис за 12 червня», цей запис було прочитано, а не «пригадалося». І кожна рефлексія починається з чесної шапки: діапазон, список завантажених файлів, покриття.
Агент не повинен вдавати, що прочитав усе
У запиті фіксуються діапазон дат, список файлів і обмеження аналізу. Якщо частина періоду не ввійшла в контекст, це зазначається у відповіді явно: «аналіз побудовано на 26 з 30 днів».
Промпт для аналізу сну, стресу і тренувань
Мій робочий промпт місячної рефлексії, адаптуйте під себе:
Проаналізуй підготовлений контекст за {місяць}.
Формат відповіді:
1. Покриття даних: скільки днів заповнено за кожною метрикою (X/30).
2. Динаміка сну, енергії, настрою, стресу: лише за заповненими днями.
3. Повторювані зв'язки (наприклад: пізній відбій → енергія наступного
дня), кожна з посиланнями на конкретні daily-записи.
4. Для кожного зв'язку: альтернативні пояснення. Кореляція не причинність.
5. Що я пообіцяв собі в минулій рефлексії і що з цього видно в даних.
6. Один маленький експеримент на наступний місяць з вимірюваним результатом.
7. Питання, які варто поставити фахівцю, якщо патерн повториться.
Заборонено: діагнози, поради щодо ліків і добавок, висновки про причини
без застережень, посилання на записи, яких немає в контексті, середні без
зазначення знаменника.
Пункт 6 — мій улюблений. Саме з нього народилася історія з мелатоніном із першої статті: рефлексія показала стабільний зв’язок «мелатонін увечері → важкий ранок», експеримент був тривіальним (два тижні без нього), і ранки вирівнялися. Не діагноз, не медичний висновок: особистий експеримент із вимірюваним результатом, який я потім обговорював уже предметно.
А іноді рефлексія ловить речі, які не є метриками зовсім. Якось у місячній зведенні з’явилася цитата з мого власного запису тритижневої давності: «коли лягаєш о 10–11, висипаєшся якісно; вчорашня енергія після пізнього відбою — везіння, а не система». Я взагалі не пам’ятав той запис. Довелося відкривати вихідний файл і переконуватися, що справді це написав. Модель не вигадала спостереження — вона його знайшла й повернула мені.
Дашборди в Obsidian: Dataview поверх frontmatter
Оскільки метрики живуть у YAML frontmatter, Dataview перетворює їх на живу таблицю місяця прямо в Obsidian:
TABLE sleep_hours, energy, mood, stress, training
FROM "daily/2026/06"
SORT date ASC
Одного погляду на таблицю достатньо, щоб побачити кластер поганих ночей або тиждень, де стрес повз угору. Плагін Charts додає поверх цього графіки. Два правила з практики: візуалізуйте пропуски, не ховайте їх — дірка в графіку сну теж є інформацією; і не будуйте «загальний AI health score» — синтетичний індекс створює хибну точність і вбиває користь окремих метрик.
Головне: vault має залишатися читабельним без плагінів узагалі. Дашборди — глазур, дані — торт.
Скільки це коштує насправді
Замість розрахунків — реальні дані з OpenRouter за два місяці використання. Чесно кажучи, до початку проєкту я очікував побачити витрати на порядок вищі. Саме тому кілька місяців відкладав ідею.
Травень 2026: я ще експериментував з моделями, частина запитів йшла через deepseek-v4-pro. Разом за місяць — $1.91, 880 запитів до pro і 159 до flash, сумарно 30+ мільйонів вхідних токенів.
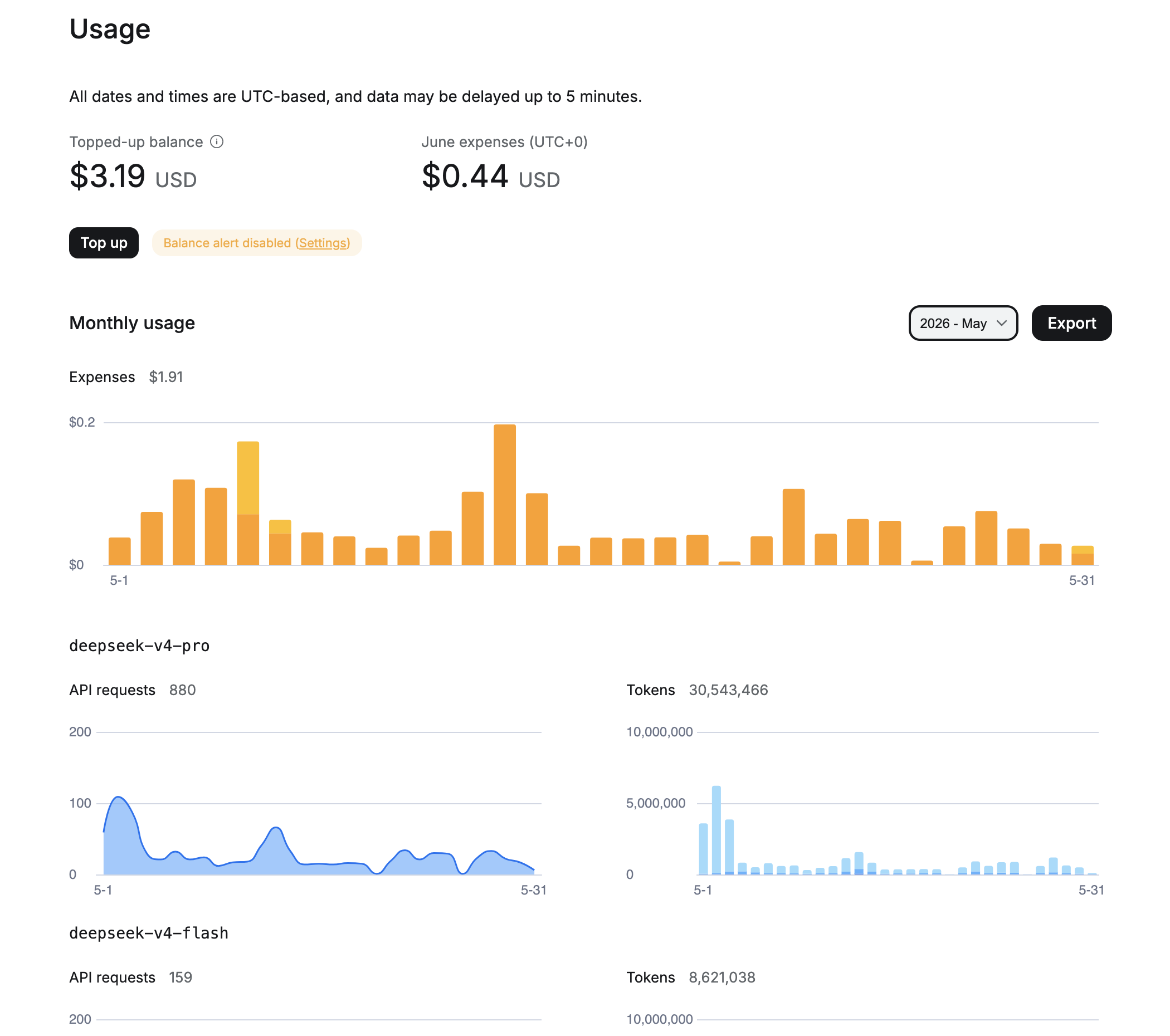
Червень 2026 (перші 13 днів): повністю перейшов на deepseek-v4-flash. 508 запитів, 26 мільйонів токенів, витрачено $0.44. У такому темпі повний місяць виходить близько $1.
Структура витрат за шарами:
| Шар | Обсяг за місяць | Реальна вартість |
|---|---|---|
| GitHub private repo | — | $0 (GitHub Free) |
| STT (локальний faster-whisper) | ~30 голосових | $0 за API, лише електрика |
| DeepSeek через OpenRouter | ~500 запитів, 26M+ токенів | ~$1/міс на flash |
| OpenAI vision (рідко) | Скриншоти та фото аналізів | Окрема змінна стаття; тримайте ліміт |
| Електрика, ноутбук 24/7 | Цілодобова робота | Залежить від тарифу і споживання |
Травень вийшов дорожчим через експерименти з pro-моделлю. Flash закриває рутинну нормалізацію дешевше і без помітної втрати якості для щоденних записів. Більш потужну модель має сенс підключати лише для рідких місячних рефлексій — і тільки на тому ж зібраному та перевіреному контексті.
Приватність і доступ до даних: хто що бачить
Повторю таблицю меж довіри з першої статті, тепер із рішеннями щодо retention:
| Шар | Що бачить | Моє рішення |
|---|---|---|
| Telegram | Усі повідомлення боту | Усвідомлений компроміс зручності |
| DeepSeek | Текст і derived text | Не надсилати документи та ідентифікатори |
| OpenAI vision | Надіслані зображення | Ліміт бюджету, жодних документів із ПІБ у кадрі |
| GitHub | Весь vault при push | Private repo + 2FA; пам’ятати: це контроль доступу, не шифрування |
| Локальний диск | Усе, включно з аудіо | Шифрування диска, полиця поза досяжністю кота |
Окрема межа довіри — телефон. У другій статті ми налаштували одностороннє дзеркало vault в iCloud для читання з iPhone, і в нього є ціна: вміст щоденника з’являється ще й у хмарі Apple. Якщо для вас це зайвий учасник, читайте щоденник лише на десктопі або використовуйте один механізм синхронізації зі зрозумілою вам моделлю довіри. Mobile-версія плагіна Obsidian Git формально існує, але експериментальна і без SSH, на неї я б не покладався.
Рішення щодо зберігання медіа: голосові я зберігаю за політикою short-retention (30 днів, потім залишається лише transcript), оригінали скриншотів живуть постійно, фото документів — окрема розмова з окремою обережністю. Який би режим ви не обрали, оберіть його до початку експлуатації і запишіть у _system/retention-policy.md: заднім числом вичищати бінарники з Git-історії — заняття на вечір і з перезаписом історії.
І процедура на випадок найгіршого: якщо в репозиторій потрапив секрет чи файл із персональними даними, просте видалення не допомагає (історія пам’ятає все). Послідовність: ротувати секрет → переписати історію → примусовий push → перевірити клони. Я розбирав такий інцидент на робочому проєкті в статті про випадково запушені секрети, але краще нехай вона залишиться для вас теоретичною: secret scan перед кожним комітом із другої статті існує саме тому.
Коли варто перейти на повністю локальні моделі
Чи можна винести й текстовий шар із DeepSeek на свій ноутбук? Технічно так: Hermes підтримує OpenAI-сумісні providers; Ollama path потрібно налаштовувати через custom_providers і перевіряти на вашій версії. Тоді назовні перестає йти навіть текст. Чесні вимоги:
- немає універсального мінімуму контексту: вимоги залежать від обраних skills, обсягу файлів і сценарію reflection;
- залізо потрібно підбирати через benchmark matrix; мій ноутбук 2019 року тягне локальний Whisper, але для пристойної локальної LLM йому вже важко;
- на моїх пробах маленькі локальні моделі частіше помилялися в структурі, але це потрібно повторити на одному synthetic fixture і опублікувати результати, а не узагальнювати за враженням.
І головне: локальна LLM не робить систему «повністю приватною». Telegram, як і раніше, бачить повідомлення, GitHub — vault. Іти в локальні моделі має сенс усвідомлено, заради конкретного шару, а не заради красивого слова self-hosted у заголовку.
Що ламається найчастіше
Таблиця відображає експлуатаційні проблеми, які проявилися за перші місяці щоденного використання, і покриває всі шари системи: Telegram gateway, розпізнавання мовлення, обох model-провайдерів, Git і сам vault.
| Симптом | Причина | Що робити |
|---|---|---|
| Бот мовчить | Gateway daemon упав або не стартував після ребуту | hermes gateway status, логи, systemd |
| Нагадування не прийшло / прийшло не вчасно | Таймзона або зупинений gateway | Тестова задача на +2 хвилини, timezone в конфізі |
| Голосові обробляються хвилинами | Whisper на CPU або модель перевантажена | Зменшити модель, перевірити GPU, заміряти латентність |
| «Не бачу зображення» | Vision-провайдер не налаштований або модель застаріла | Звірити model ID, ключ, ліміти |
| Помилка провайдера тексту | Закінчився баланс або змінився model ID | Баланс DeepSeek, актуальний ID |
| Push відвалюється | SSH-ключі, токен, мережа | ssh -T [email protected]; записи накопичуються локально, нічого не втрачається |
| Дублікати записів за день | Зламана upsert-логіка в skill | Canonical шлях, фікстура з кроку 12 другої статті |
| Репозиторій розпух | Аудіо і фото в Git | Retention policy, чистка за правилами, не «на око» |
За перші місяці ця таблиця покрила більшість моїх експлуатаційних збоїв і допомагала швидко зрозуміти, з якого шару починати діагностику.
Що залишилося після перших місяців
Щоденник працює не тому, що модель розумна, а тому, що записати день стало дешевшим за те, щоб не записувати. Все інше — наслідки, які я зрозумів не з архітектури, а з конкретних епізодів.
Якось я на тиждень випав із звички: відрядження, збився режим, бот надсилав нагадування в порожнечу. Коли повернувся й побачив сім порожніх днів у vault, перший імпульс був — заповнити їх задніми числами з пам’яті. Не зробив. Лишив дірки. Відтоді я значно спокійніше ставлюся до пропусків: тридцять недосконалих записів корисніші за сім ідеальних, бо лише вони справжні.
Найбільше проблем мені створила не модель, а одного разу зламана схема запису. Я змінив одне поле у frontmatter без міграції старих файлів, і тижнева зведення почала рахувати статистику по-різному для старих і нових днів. Я помітив це лише через три тижні, коли цифри почали виглядати дивно. Після цього я почав значно більше довіряти нудним правилам: canonical імена файлів, жорстка схема, словник виправлень — вони дали мені більше, ніж будь-який апгрейд моделі.
І ще: сирі записи я тепер не чіпаю ніколи. Всі інтерпретації можна перерахувати, втрачений оригінал не повернути. Це стало зрозуміло того дня, коли я спробував «покращити» один старий запис і втратив нитку того, що я насправді думав того вечора.
Щоденник не зробив мене здоровішим сам по собі. Він зробив видимими наслідки рішень: пізній серіал, мелатонін, три погані ночі перед залом. Рішення як і раніше за мною, і частину з них я як і раніше приймаю неправильно, але тепер хоча б усвідомлено.
Старий ноутбук так само стоїть на полиці, кіт так само невдоволений, а в мене вперше в житті щоденник пережив четвертий місяць. Для людини, яка кинула всі трекери на третьому тижні, це найкраща метрика з можливих.
За ці місяці агент не перетворився на лікаря, психолога чи всезнаючого Джарвіса. Зрештою він виявився не розумним порадником. Скоріше системою, яка не дає мені забути те, що я сам собі вже говорив місяць тому. Він не проживає день за мене й не обіцяє зрозуміти мене краще за мене самого. Він допомагає не втрачати факти й повертатися до власних слів вчасно, а не через рік.
На цьому серія закінчується там само, де починається щоденна практика: о 21:00 телефон вібрує, я затискаю кнопку запису й сорок секунд розповідаю, як минув день. Різниця лише в тому, що тепер за цією простою дією стоїть не черговий закритий сервіс, а історія, яка належить мені.
FAQ
Це замінить лікаря чи психолога?
Ні. Система збирає спостереження і допомагає готувати питання. Будь-які рішення про здоров’я — з фахівцем, будь-які тривожні симптоми — до лікаря напряму, а не в щоденник.
Модель не почне «діагностувати» сама?
Почне, якщо їй дозволити: моделі люблять робити впевнені висновки. Тому обмеження зашиті в skill і в промпт рефлексії, а не тримаються на чесному слові. Розділ «Заборонено» в промпті — найважливіша його частина.
Що, якщо я пропускаю дні?
Нічого. Пропуск — це дані, а не провал. Зведення показують покриття («сон: 24/30 днів»), і система ніколи не вигадує значення за пропущені дні. Повертатися після перерви не соромно: бот не дорікає, він просто продовжує.
Чи можна вести щоденник двома мовами?
Так, Whisper справляється зі змішаним мовленням, а нормалізація приводить усе до однієї схеми. Я диктую українською і планую перейти на англійську: щоденна диктовка — чудова розмовна практика, а структура записів від мови не залежить.
Чому не віддати все одному сильному асистенту з пам’яттю?
Тому що пам’ять асистента — це не ваші дані. Це внутрішній стан чужого сервісу: ви не можете його вивантажити цілком, перевірити, що там лежить, або перенести до іншого провайдера. Markdown-файли в моєму Git переживуть будь-якого провайдера, будь-яку підписку і будь-яку зміну політик: навіть якщо завтра зникнуть і Hermes, і DeepSeek, у мене залишиться повний архів записів, який читається чим завгодно. Плюс retention вирішую я: що зберігати, скільки і коли видалити. З пам’яттю сервісу всі ці рішення ухвалює сервіс.
З чого почати, якщо три статті — це забагато?
З однієї звички: поставте нагадування на 21:00 і тиждень відповідайте на нього голосовою нотаткою хоч у «Збережені повідомлення». Якщо звичка приживеться, повертайтеся до другої статті і збирайте повну систему: їй буде, що обробляти.