TL;DR
- Старий ігровий ноутбук 2019 року став домашнім сервером для персонального AI-агента: він уміє виконувати звичайні доручення, але його головна роль для мене — супроводжувати фізичний та емоційний стан на довгій дистанції.
- Через Telegram агент приймає щоденникові записи, результати аналізів, документи й тренування, нагадує про важливі події та перетворює розрізнені повідомлення на пов’язану історію в Markdown.
- Hermes Agent оркеструє процес, DeepSeek опрацьовує рутинний текст, мовлення розпізнається локально, зображення йдуть через окремий vision-шар.
- Це інструмент спостереження й саморефлексії, а не лікар чи психолог: система допомагає помічати патерни й формулювати питання, але не замінює професійну допомогу.
Частина 1 з 3: ідея, архітектура та перші патерни
21:00, вівторок: як працює мій AI-щоденник самопочуття
Теплий вечір на Коста-Бланці. Телефон коротко вібрує. Це не робочий месенджер і не новини. Це мій власний бот, і він питає те саме, що й учора, і позавчора: як минув день, як сон, енергія, настрій, стрес, чи була тренування.
Я не відкриваю жодного застосунку з формами та повзунками. Я затискаю кнопку запису в Telegram і сорок секунд говорю, як є: спав близько семи годин, зранку була силова, надвечір енергія просіла, день загалом нормальний. Відпускаю кнопку й повертаюся до своїх справ.
Далі відбувається те, заради чого все й затівалося. В іншій кімнаті тихо шумить вентиляторами ноутбук, на якому я колись грав. Він приймає голосове повідомлення, локально перетворює мовлення на текст, зводить сказане до структурованого Markdown-запису, зберігає оригінал поруч із підсумком, робить commit і відправляє його в приватний репозиторій. За кілька секунд бот надсилає коротке підтвердження й одне уточнювальне питання, якщо я щось забув назвати.
Увесь мій «запис у щоденник» зайняв менше хвилини. Але щоденник — лише одна роль універсальнішого персонального агента. Його можна попросити знайти квитки, розібрати документ, написати листа, допомогти з кодом або нагадати про зустріч. Найцінніше застосування, яке я для нього знайшов, виявилося іншим: супроводжувати мій фізичний та емоційний стан на довгій дистанції.
Я називаю його агентом для самоспостереження. Він приймає текст, голос і фото, зберігає результати аналізів і медичні документи, записує тренування та прогрес, збирає мої спостереження про сон, енергію, стрес і настрій. А потім повертає все це не розсипом повідомлень, а пов’язаною історією в моїх власних Markdown-файлах.
Це не медичний продукт
Система призначена для особистого журналювання та підготовки питань до фахівця. Вона не є медичним пристроєм, не ставить діагнозів, не призначає лікування й не замінює лікаря чи екстрену допомогу.
Ноутбук, який п’ять років чекав нову роботу
У 2019 році я купив Xiaomi Mi Gaming Laptop і був ним щиро задоволений. Гарне залізо, дискретна відеокарта, вечори за іграми. Покупка цілком себе виправдовувала, поки я мав час її виправдовувати.
Із 2021 року я практично перестав грати. Не з принципу, просто на ігри перестало вистачати часу. У 2022 році почалося повномасштабне вторгнення в Україну, і того ж року народилася моя донька. Пріоритети перезібралися повністю, і ноутбук закрився востаннє на кілька років. Він стояв на полиці, дорогий і безкорисний, і щоразу, коли погляд на нього падав, було трохи шкода: усередині все ще гарне залізо, включно з GPU, якому ніхто не давав роботи.
На початку 2026 року хвиля інтересу до персональних AI-агентів підказала очевидну в ретроспективі думку: always-on агенту потрібна постійно працююча машина, а в мене така машина вже є. Старий ігровий ноутбук пасує на роль домашнього сервера краще, ніж здається: він тихіший за серверну стійку, у нього є «безкоштовний вбудований ДБЖ» у вигляді батареї, а його GPU може локально ганяти моделі розпізнавання мовлення.
Сьогодні він стоїть у моєму домашньому офісі, на відкритій настінній полиці, трохи вище за рівень голови. Висота не дизайнерське рішення: у квартирі живе кіт, який вважає будь-яку теплу техніку своєю власністю, і полиця залишається єдиним місцем, куди він поки не дострибнув. Так колишній ігровий флагман став найдивнішим сервером з усіх, що я бачив: стоїть між книжками, підключений до розетки й роутера й тихо робить git push, поки кіт незадоволено дивиться на нього знизу.
Із цього епізоду виріс головний принцип усієї затії: не купувати нове залізо під експеримент, а дати друге життя тому, що вже є. Якщо експеримент провалиться, я втрачу лише час.
Мій поки що зовсім молодий Джарвіс
Коли говорять про персонального AI-агента, легко уявити універсального помічника: знайти квитки, написати листа, розібрати документ, допомогти з кодом, поставити нагадування. Мій агент теж здатний на такі доручення. Але досить швидко я зрозумів, що його найцінніша для мене роль лежить поза роботою. AI-агентів у робочому workflow я й так маю достатньо. Мені хотілося помічника для тієї частини життя, яка зазвичай провалюється між календарем, нотатками, медичними PDF, застосунком для тренувань і власною пам’яттю.
Щось середнє між щоденником, секретарем, архіваріусом, уважним співрозмовником і тренером, який не кричить про дисципліну. Агент зберігає результати аналізів і допомагає порівнювати їх через місяць. Записує тренування, ваги й прогрес. Збирає спостереження про сон, енергію, харчування, стрес і настрій. Нагадує про лікарів та інші важливі події. А ввечері вислуховує розповідь про мій день і повертає її мені в ясній формі.
Звичайне нагадування повідомило б: «Прийом у хірурга у вівторок о 9:45». Агент може додати контекст: «Ти зараз в Іспанії — заздалегідь подумай про перекладача для візиту». Це все ще проста cron-задача, а не магія. Але вона використовує збережений контекст і говорить зі мною у вибраному тоні.
Можливо, колись персональні агенти справді стануть схожими на Джарвіса або цифрового фамільяра, який супроводжує людину роками. Мій поки значно молодший: живе на старому ноутбуці, пише Markdown-файли й іноді нагадує підготувати перекладача до лікаря. Але головне вже вміє: зберігати контекст мого життя довше, ніж його утримує моя пам’ять.
Ззовні все це підозріло схоже на звичайний щоденник. Але за кілька тижнів записи починають працювати інакше: пам’ять згладжує деталі, один поганий день здається випадковістю — а послідовні записи показують повторювані зв’язки між сном, навантаженням, тренуваннями й настроєм, які я сам не помічаю.
Агент не знає мене краще за лікаря чи психолога й не повинен удавати, що знає. Його завдання скромніше: допомогти уважніше спостерігати за собою, сформулювати думки й питання та не втратити важливі деталі між консультаціями.
Я багато разів починав вести щоденники й трекери. В якийсь момент у мене накопичилася ціла колекція напівкинутих застосунків і нотаток, де останній запис виглядав приблизно як «починаю вести регулярно». Усі вони помирали однаково: на третьому тижні заповнювати форму стає ліньки, пропуски накопичуються, звичка розсипається. Голосове повідомлення в Telegram лінню не вбити: сорок секунд мовлення замість п’яти полів форми.
Питання було лише в тому, хто перетворить цей потік свідомості та розрізнені вкладення на структуровані дані. Так з’явилося ядро вимог: агент має приймати текст, голос і зображення, зберігати контекст у явних записах, виконувати доручення за розкладом і давати формат, який переживе будь-який сервіс. Тобто Markdown-файли під версійним контролем.
Місяць із OpenClaw: вражаюче, але не для мене
Першою спробою став OpenClaw, який позиціонується як personal AI assistant на власних пристроях. Звучало як точне влучання в моє завдання, і можливості справді вражали: безліч каналів, companion-застосунки, multi-agent routing, широка екосистема автоматизацій.
Я налаштовував і використовував його близько місяця. В якийсь момент я помітив, що другий вечір поспіль лагоджу інфраструктуру замість того, щоб користуватися щоденником. Використовую відсотків десять платформи, а обслуговую всі сто. Для широкої multi-channel системи такий масштаб може бути виправданим, але мій сценарій був один: єдиний користувач, один Telegram-канал, один щоденний workflow. Це не висновок про надійність OpenClaw загалом, а лише результат мого досвіду з однією конфігурацією.
Через місяць стало зрозуміло, що мені потрібен не майданчик на всі випадки, а один стабільний сценарій, який працює щодня. Кожен компонент, який я не використовую, все одно вимагає моєї уваги, коли ламається.
Чому підписки не стали інфраструктурою
Паралельно я вперся в питання, на чому це все має думати. Перша думка була очевидною: у мене вже оплачені підписки на сильні моделі, чому б агенту не використати їх. Я експериментував із доступом через підписочні продукти й суміжний інструментарій, але швидко зрозумів, що будувати особисту інфраструктуру на цьому не можна: політики доступу для сторонніх агентів у провайдерів змінювалися, і subscription-backed доступ виявився нестабільною основою, що залежить від поточних правил, а не від моїх рішень.
Гаразд, тоді чесні API-виклики. І тут на мене чекала друга незручна правда: постійно працюючий агент із heartbeat, cron-задачами й tool calls споживає токени зовсім не так, як чат, у який заходиш пару разів на день. За прямої оплати преміальних моделей рутинний фон обходиться суттєво дорожче, ніж здається з досвіду звичайного чату.
Звідси наступний висновок: для рутинного навантаження потрібна дешева модель, а сильну лишити для рідкісних складних задач. Нормалізація вечірнього голосового повідомлення в структурований запис не потребує флагманського інтелекту. Це конвеєрна робота: класифікувати, видобути, відформатувати.
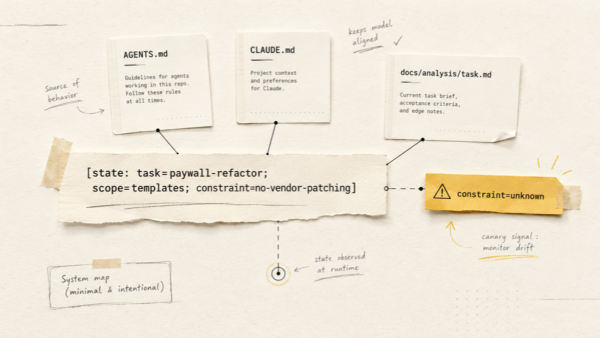
Вимоги до системи: один користувач, Telegram і Markdown
Після місяця з OpenClaw і експериментів з провайдерами список вимог стиснувся до чесного мінімуму:
- один користувач: я;
- один інтерфейс: Telegram, бо він уже завжди під рукою;
- три формати входу: текст, голосові повідомлення, зображення;
- щоденник фізичного та емоційного стану без обов’язкових форм;
- тренування, результати аналізів і документи в спільній хронології;
- щоденний check-in і персоналізовані нагадування;
- контекст зберігається в явних файлах, а не в обіцянці, що модель «все пам’ятає»;
- вихід: структурований Markdown у моїй файловій системі;
- версіонування та backup: приватний Git-репозиторій;
- передбачувана вартість рутинної обробки;
- мовлення розпізнається локально після доставки через Telegram, без окремого хмарного STT-провайдера.
По суті це вимоги до self-hosted рішення: локальний AI-агент на власній машині всюди, де це практично, і хмарні сервіси лише там, де вони дають непропорційно багато за свої компроміси.
Під цей список я й вибирав заново.
Чому Hermes Agent і DeepSeek
Після дослідження я перейшов на Hermes Agent. У нього дві ролі, які часто змішують: оркестратор і модель. Hermes нічого не «думає» сам, він керує процесом: приймає повідомлення через Telegram gateway, запускає розпізнавання мовлення, викликає модель, виконує skills, працює з файлами й виконує cron-задачі. А думає підключена модель, і її можна міняти.
Для рутинного тексту я вибрав DeepSeek: Hermes підтримує його як прямого провайдера, а вартість масової текстової нормалізації в нього низька. Для класифікації, видобування фактів і сумаризації щоденних записів цього достатньо. Сильну модель можна підключати точково, наприклад для місячної ретроспективи, як опціональний рівень, а не обов’язковий default.
Порівняння з OpenClaw за моїми критеріями виглядало так:
| Критерій мого проєкту | OpenClaw | Hermes Agent | Чому це важливо мені |
|---|---|---|---|
| Personal always-on assistant | Підтримується | Підтримується | Базова вимога |
| Telegram | Підтримується | Підтримується | Головний інтерфейс |
| Skills + cron | Підтримуються | Підтримуються | Щоденний check-in |
| Широка multi-channel платформа | Сильна сторона | Є gateway, але мій setup вужчий | Мені не потрібні десятки інтеграцій |
| Дешева routine-модель | Багато provider-опцій | Прямий DeepSeek provider | Передбачувана вартість |
| Локальне розпізнавання мовлення | Потребує окремого посилання на актуальну документацію OpenClaw | faster-whisper | Після Telegram аудіо не йде ще й у зовнішній STT API |
| Markdown workspace | Можна налаштувати | Використовується безпосередньо | Obsidian і Git workflow |
| Підсумок для мене | Потужніший за мої вимоги | Достатній для вузького pipeline | Особистий вибір, не універсальний benchmark |
Підкреслю ще раз: це не вердикт «Hermes кращий за OpenClaw». Це висновок для одного конкретного single-user сценарію, мого. Після переходу головна метрика стала не «скільки інтеграцій потенційно доступно», а «скільки вечорів я не витрачаю на обслуговування системи». У моєму вузькому pipeline ця метрика різко покращилася: я перестав обслуговувати платформу й почав користуватися щоденником.
Про зображення: як влаштований шлях картинок
DeepSeek у моїй конфігурації відповідає за текст. Скриншоти тренувань і фото документів ідуть через окремий допоміжний vision-шар: у мене це невеликий бюджет OpenAI API, який я підключаю за бажанням і використовую досить рідко. Тож текст і зображення проходять двома різними шляхами, і в другій статті я налаштовую vision-шар окремим кроком.
Що реально працює в мене зараз
Перед встановленням агента я повністю очистив диски, видалив Windows і поставив Ubuntu. Було трохи дивно остаточно знести систему, на якій кілька років грав, — але машина більше не ігрова, їй не потрібне минуле. Жодного dual boot: для цілодобового сервісу чиста система означає менше зайвих програм, фонових процесів і несподіванок під час оновлень.
Це не концепт і не вихідні з прототипом. Система працює в щоденному режимі з лютого 2026 року; на початок червня 2026 року в private workflow було близько 80 daily notes. Конфігурація на момент написання (перевірено: 2026-06-07):
Hardware: Xiaomi Mi Gaming Laptop (2019), GPU: GTX 1060 Mobile 6 GB + Intel UHD 630
OS: Ubuntu 24.04.4 LTS, kernel 6.17.0-22-generic, x86_64
Role: always-on домашній AI-сервер
Оркестратор: Hermes Agent v0.12.0 (2026.4.30), commit 4f3766917
Main model: DeepSeek (deepseek-v4-flash), прямий API
Gateway: Telegram через systemd user service
STT: faster-whisper 1.2.1, medium, CUDA, int8_float32
Vision/OCR: невеликий бюджет OpenAI API як auxiliary vision layer
TTS: Edge TTS
Workspace: локальний Markdown-репозиторій + приватний Git remote
Датований знімок gateway на 2026-06-07: 35 днів uptime, близько 5.7 GB RAM, CPU time 6h27min. Енергоспоживання не підтверджено: на машині немає надійного датчика, потрібен зовнішній ватметр.
Voice path перевірено на GPU
На 2026-06-07 локальний STT знову працює end-to-end: faster-whisper 1.2.1, модель medium, GTX 1060 6 GB через CUDA 12.2, compute type int8_float32. Тестове аудіо тривалістю 22 секунди розпізнано за 2.17 секунди.
Як минає один звичайний день
Зранку силова тренування в залі. Я записую її, як і раніше, у Hevy, роблю скриншот підсумків і відправляю боту. Vision-шар видобуває вправи, підходи й ваги, skill зберігає оригінал скриншота як attachment і структуровані поля тренування поруч, у тій самій даті. Калорії я рахую в YAZIO і скидаю боту лише денне саммарі: дублювати кожен прийом їжі немає сенсу. У теорії і тренування, і харчування можна вести цілком через бота, без сторонніх сервісів, але це вже наступний рівень, який я лишив на потім.
Удень система мовчить. Це важлива властивість: хороший щоденник не випрошує уваги.
О 21:00 приходить нагадування. Я відповідаю голосом: сон, енергія, настрій, стрес, події дня. Дружина до цього вже звикла й не озирається, коли я ввечері диктую щось телефону. Доньці чотири, і для неї бот поки не існує. Локальний faster-whisper робить transcript, skill видобуває лише явно сказані факти й нормалізує шкали. Якщо я забув щось обов’язкове, бот ставить одне компактне уточнювальне питання, а не анкету з п’яти повідомлень. Досвід показав: одне коротке уточнення зберігає звичку, анкета її вбиває.
У підсумку за дату з’являється один Markdown-запис: сирий transcript окремо, нормалізована зведення окремо, метрики в YAML frontmatter (sleep_hours, sleep_quality, energy, mood, stress, training), посилання на джерела. Git commit фіксує версію. Повторне повідомлення за ту саму дату оновлює наявний запис, а не плодить дублікати.
А у відповідь бот надсилає коротке зведення того, що він зрозумів із моєї диктовки. Виглядає це приблизно так (приклад синтетичний, усі деталі змінено, але інтонація справжня):
🛌 Сон: обіцяв собі лягти о 22:00, але серіал знову переміг. Ліг опівночі, встав о 7 — разом 7 годин замість запланованих дев’яти.
🏋️ Зал: ноги і прес, тренування далося важко після короткої ночі.
💼 Робота: два релізи й пара багфіксів, день щільний, без обіду.
🚶 10 000 кроків закрито, але почалися лише о п’ятій вечора — недосип дається взнаки.
⚡ Енергія 4/10 — непогано тримаєшся для такої ночі.
Тон цього зворотного зв’язку задається інструкціями skill: наскільки асистент м’який чи в’їдливий, хвалить він чи підколює, чи дає міні-поради на запит. У публічному прикладі це залишається безпечним налаштуванням тексту, а не медичною інтерпретацією. Мій зараз у режимі «друг із легкою іронією», і читати вечірнє зведення стало маленьким ритуалом: приємно, коли твій день хтось акуратно складає в три рядки, навіть якщо цей хтось працює на полиці, щоб кіт його не дістав.
Одну історію варто розповісти чесно. У перші тижні я кілька разів знаходив у записах дивні цифри: Whisper чув диктовку правильно, але DeepSeek при нормалізації іноді міняв числа місцями. Я продиктував «сон шість годин, настрій чотири», а в YAML frontmatter вийшло sleep_hours: 4, mood: 6. Жодної помилки в логах — запис пройшов нормально. Я помітив лише тому, що тижнева зведення показала середній сон 4.3 години, і це явно не збігалося з відчуттями того тижня. Довелося додати в skill явну інструкцію: кожне числове поле повторюється в підтвердженні, і я пробігаю по ньому очима перед тим, як закрити телефон. Це додало п’ять секунд до ритуалу й прибрало тиху помилку, яка могла накопичуватися місяцями.

А за кілька тижнів накопичені записи починають працювати на мене: я можу попросити тижневу чи місячну ретроспективу сну, навантаження, стресу й настрою. Як саме це влаштовано без ілюзії «агент пам’ятає все», розповім у третій статті.
Патерни, які знайшов щоденник: серіали, сон і мелатонін
Будь-який трекер живе до першого «навіщо я це роблю». У мене це питання закрилося за пару місяців, коли записи накопичилися й у них стали видні патерни, які за пам’яттю я б ніколи не зібрав.
Перший патерн банальний, але в цифрах він б’є сильніше, ніж у відчуттях. Вечір, «ще одна серія», екран гасне до першої ночі, підйом о сьомій. Я й так знав, що не висплюся. Але щоденник показав картину цілком: наступного дня після такого вечора в мене не лише розбитість до обіду, а й вага не падає, а росте, хоча харчування не змінювалося. Одна річ невиразно здогадуватися, інша: бачити, як одна й та сама зв’язка повторюється в записах раз за разом. Серіали в будні я після цього не кинув повністю, але торгуватися із собою стало значно важче.
Другий патерн виявився для мене несподіваним. Я якийсь час приймав мелатонін перед сном і вважав його безневинним помічником. Записи показали зворотне: у дні після мелатоніну я ледве прокидався й півдня приходив до тями, і ця зв’язка повторювалася надто стабільно, щоб списати її на збіг. Для мене він працював як ручне гальмо на весь ранок. Я перестав його вживати, і ранки вирівнялися.
Це спостереження, а не рекомендація
Обидва приклади: мої особисті кореляції з мого щоденника, а не медичні висновки. Реакція на мелатонін індивідуальна, і рішення про вживання добавок варто обговорювати з фахівцем. Цінність щоденника саме в тому, що на прийом до нього приходиш не з «мені якось не дуже», а з конкретною картиною за місяць.
Саме в цьому для мене сенс усієї системи. Не «AI стежить за здоров’ям», а дешевий за зусиллями збір спостережень, у яких потім видно закономірності, і з яких виходять конкретні питання замість невиразних скарг.
Що змінилося, крім кількості Markdown-файлів
Найпомітніша зміна виявилася не технічною. Раніше поганий день зазвичай закінчувався коротким висновком: «втомився», «нічого не встиг», «завтра треба зібратися». Тепер вечірній запис змушує розкласти це відчуття на частини. Може виявитися, що робота йшла нормально, але я мало спав, пропустив обід і надвечір уже не міг адекватно оцінити власний день. Така проста декомпозиція не розв’язує проблему, але повертає їй правильний розмір.
Іноді агент не повідомляє нічого нового. Він лише формулює те, що я вже знав, але не встиг назвати. Для мене це теж корисно: рефлексія вбудована в той самий короткий ритуал, що й запис фактів.
З’явився і практичний ефект перед консультаціями. Замість спроби пригадати останні кілька тижнів я можу відкрити хронологію: коли змінився сон, як змінювалося навантаження, що я приймав, які показники прийшли в аналізах і що сам відзначав у щоденнику. Ці записи не дають медичної відповіді, зате допомагають принести фахівцю точніше питання.
Агент також поступово стає інтерфейсом до моєї власної історії. Я можу запитати не лише «як я спав цього тижня», а й «коли востаннє боліло коліно після присідань», «яка вага була в жимі місяць тому» або «що я хотів обговорити з лікарем». Відповідь цінна не тому, що модель розумна, а тому, що під нею лежать датовані джерела, які можна відкрити й перевірити.
Головний принцип: відповідь має вести до джерела
Якщо агент робить висновок з історії, він має вказувати дати й записи, на яких цей висновок ґрунтується. Інакше впевнений текст легко сприйняти за пам’ять системи, хоча це може бути лише правдоподібна генерація.
Архітектура: хто що робить
Я / телефон
├─ текстовий check-in
├─ голосова нотатка
├─ скриншот тренування
└─ фото документа
│
▼
Telegram Bot (суворий allowlist: тільки я)
│
▼
Hermes Gateway (старий ноутбук, Ubuntu, systemd)
├─ STT: локальний faster-whisper
├─ Main LLM: DeepSeek (нормалізація тексту)
├─ Auxiliary vision: окремий провайдер для зображень
├─ wellbeing skills (journal + reflection)
└─ cron: нагадування о 21:00, періодична рефлексія
│
▼
Локальний Markdown vault (записи + attachments)
│
├─ Obsidian для перегляду та дашбордів (Dataview)
└─ Git commit → приватний GitHub-репозиторій
(версійний backup, не E2EE-сховище)

Кожен блок у цій схемі з’явився не з любові до архітектури, а з конкретного епізоду історії вище: ноутбук дав local inference, OpenClaw навчив звужувати scope, ціни на API привели до DeepSeek, небажання відправляти голос у хмару привело до локального Whisper, а страх втратити роки записів привів до Git. Записи при цьому лежать у YAML frontmatter плюс вільний текст, і Obsidian читає їх як звичайний vault: метрики для дашбордів, текст для людини.
Де проходять межі довіри
«Лежить в Obsidian» не означає «лежить локально». Чесна таблиця того, хто що бачить:
| Учасник | Що отримує | Чим це контролюється |
|---|---|---|
| Telegram | Вміст усіх повідомлень боту | Це усвідомлений компроміс зручності |
| Локальний STT | Не отримує окрему зовнішню копію: розпізнавання виконується на ноутбуці | faster-whisper на моєму GPU; вихідне повідомлення вже пройшло через Telegram |
| DeepSeek | Текст повідомлень і derived text | Лише те, що я відправив сам |
| Vision-провайдер | Надіслані зображення | Окремий ключ і бюджет |
| GitHub | Вміст vault при push | Private repo: контроль доступу, не шифрування |
| Локальний диск | Усе | Шифрування диска й фізичний доступ |
Приватний репозиторій не дорівнює шифруванню
Private GitHub repository обмежує доступ, але не є end-to-end encrypted медичним сховищем і автоматично не робить рішення HIPAA/GDPR-compliant. Якщо дані пройшли через Telegram, хмарну модель чи GitHub, ці сервіси входять у модель загроз. Детальний розбір: у третій статті.
Що ця система вміє і чого не вміє
Уміє:
- приймати текст, голос і зображення без відкривання форм;
- перетворювати потік свідомості на структуровані записи з єдиною схемою;
- вести хронологію тренувань, показників, аналізів і документів;
- зберігати сирий ввід окремо від інтерпретації моделі;
- надсилати персоналізовані нагадування з доречним збереженим контекстом;
- питати про минулий день і ставити одне уточнення замість анкети;
- версіонувати все в Git, включно з історією виправлень;
- готувати тижневі й місячні ретроспективи як гіпотези для саморефлексії.
Не вміє й не повинна:
- ставити діагнози й інтерпретувати симптоми як заміну лікарю;
- радити міняти ліки чи дозування;
- робити висновки про причинність із кореляцій;
- «знати» точність OCR: розпізнані з фото дані завжди позначаються для ручної перевірки;
- гарантувати конфіденційність понад межі з таблиці вище.
Якщо запис містить тривожні симптоми, правильна дія системи одна: порадити звернутися по допомогу, а не намагатися «проаналізувати».
Чесні обмеження: що варто знати заздалегідь
Я свідомо не публікую репозиторій із готовим кодом. Vault зберігає особисті дані: тренування, симптоми, документи. Викладати його як шаблон немає сенсу, а скелет без даних і скілів не дає жодної цінності. Hermes Agent — відкритий фреймворк, і обв’язку під себе кожен пише під власні задачі. Для senior-розробника це робота на пару вечорів; для тих, хто лише знайомиться з агентами, другий мануал у цій серії стане гарною стартовою точкою.
Система не є повністю безкоштовною. Локальний faster-whisper і DeepSeek через OpenRouter справді дешеві: мій рутинний фон обходиться в кілька доларів на місяць. Але якщо ви активно використовуєте vision-шар для OCR документів та аналізу скриншотів, витрати зростають. Я застосовую його рідко й цілеспрямовано, тому для мене це не проблема. Детальну розбивку вартості за шарами наведено в третій статті.
Старий ноутбук — це single point of failure. Вимкнули світло вдома, завис Wi-Fi, перегрілася батарея під навантаженням: щоденник недоступний. Для мене це прийнятний компроміс, відсутність запису за один вечір — не катастрофа. Якщо ви будуєте систему для критично важливого медичного трекінгу, варто подумати про резервний канал або хмарне резервування. Я свідомо на це не пішов: приватність важливіша за мене, ніж 99,9% аптайму особистого щоденника.
Замість висновку: помічник починається з пам’яті
Коли я діставав ноутбук із полиці, я думав, що експеримент буде про AI. Виявилося, він про записи. За кілька місяців найнесподіваніший висновок для мене звучить так: неважливо, наскільки розумна модель, якщо їй нема на що спертися. Вся корисність системи виросла не з LLM, а з накопичених датованих записів, які можна відкрити й перевірити. Модель просто навчила мене робити їх регулярно.
Для мене цього вже достатньо, щоб старий ігровий ноутбук більше не здавався старим.
Що в частині 2 і частині 3: встановлення та експлуатація
Частина 2: Встановлення з нуля на чистій Ubuntu — Hermes Agent, підключення DeepSeek, Telegram-бот із закритим доступом, локальний faster-whisper, окремий vision-шар, структура vault, обидва skill, приватний Git і нагадування на 21:00. Кожен крок із перевіркою та розділом «якщо не спрацювало».
Частина 3: Життя зі щоденником після встановлення — виправлення помилок розпізнавання, робота зі скриншотами й документами, тижневі зведення, чесна місячна рефлексія без вигаданого RAG, дашборди в Obsidian, реальна вартість за шарами й приватність.
FAQ
Це заміна лікарю чи медичний застосунок?
Ні. Це особистий журнал спостережень. Його максимум: допомогти помітити патерни й підготувати більш структуровані питання до фахівця.
Чому не готовий health-застосунок?
Застосунки вимагають заповнювати їхні форми й зберігають дані у своїх форматах. Тут вхід вільний (голос, текст, фото), а вихід: мої власні Markdown-файли, які переживуть будь-який сервіс.
Чи обов’язковий старий ігровий ноутбук?
Ні, підійде будь-яка постійно працююча машина з Ubuntu. GPU прискорює локальне розпізнавання мовлення, але faster-whisper працює і на CPU, повільніше.
DeepSeek розуміє картинки?
У моїй конфігурації DeepSeek займається текстом, а за зображення відповідає окремий допоміжний vision-шар через OpenAI API. Це два різні бюджети й два різні кроки налаштування. Vision я підключаю за бажанням і користуюся ним досить рідко, тож без нього текст і голос працюють повністю.
Наскільки це приватно?
Голосове повідомлення проходить через Telegram, але після доставки розпізнається локально й не відправляється окремому STT-провайдеру. Текст бачить DeepSeek, зображення бачить vision-провайдер, а vault зберігається в приватному GitHub. Це усвідомлені компроміси, і в третій статті я розберу їх за шарами.
Скільки це коштує на місяць?
Рутинна текстова обробка на DeepSeek коштує мало, vision-шар оплачується окремо, локальне розпізнавання мовлення коштує лише електрики. Точну формулу й датований знімок цін я даю в третій статті.
Якою мовою диктувати нотатки?
Я диктую українською, faster-whisper справляється впевнено. У планах перейти на англійську: щоденна диктовка про власний день виглядає як ідеальна розмовна практика дорогою до C1, а щоденник при цьому продовжить працювати, як і раніше.