TL;DR
- El valor de un diario de IA no aparece el día de la instalación, sino al cabo de un mes, cuando las entradas empiezan a formar patrones: sueño, estrés, entrenamientos, estado de ánimo.
- El agente no «recuerda todo el vault» de forma automática: una reflexión mensual honesta exige reunir el contexto de los archivos de manera explícita, y te enseño cómo.
- Las conexiones que encuentras son hipótesis para observar y preguntas para el especialista, no diagnósticos.
La primera noche después de instalarlo abrí varias veces la carpeta del diario para comprobar que el archivo había aparecido de verdad. Al día siguiente revisé el commit. Una semana después noté que ya no abría la carpeta después de cada entrada. Y otro mes más tarde no podía recordar cuándo había revisado los logs por última vez de forma manual. Era una buena señal: la herramienta había desaparecido de mi atención y solo había quedado el hábito.
En el primer artículo conté cómo un viejo portátil gaming se convirtió en un servidor de IA doméstico, y en el segundo montamos el sistema desde cero. Este artículo trata de lo que pasa después, cuando se acaba la euforia del «¡funciona!» y el recordatorio de las 21:00 sigue llegando cada noche: trata de la operación diaria y del análisis de diario con IA cuando ya has acumulado entradas suficientes.
Parte 3 de 3: operación, reflexión y coste
Qué cambia después del primer mes
La primera semana juegas con el sistema: mandas notas de voz, miras cómo crece el vault, le enseñas capturas al bot. Para la tercera semana la novedad se evapora y queda el mecanismo desnudo del hábito: la vibración a las 21:00, cuarenta segundos de dictado, confirmar, y ya está. En ese momento, la cualidad principal del sistema no resulta ser la inteligencia del modelo, sino la ausencia de fricción. Si tuviera que abrir una app y rellenar un formulario, ya lo habría dejado.
Hacia el primer mes empecé a hacerle preguntas al diario en vez de limitarme a archivar entradas. No ‘¿cómo estoy hoy?’ — eso ya lo sé — sino ‘¿por qué la segunda semana seguida el jueves estoy agotado?’. Un día no tiene respuesta a esa pregunta. Treinta días sí.
Lo muestro con un ejemplo compuesto sacado de mi práctica: los detalles están cambiados para no publicar entradas reales. Tres noches seguidas de sueño interrumpido: miércoles, jueves, viernes. Por separado, cada noche parecía una casualidad: el calor, una serie hasta tarde, simplemente no pegar ojo. Y el sábado el entrenamiento, de repente, costó más de lo normal. En el momento parecía «un mal día en el gimnasio». En el diario, la falta de sueño acumulada se convirtió en una hipótesis de trabajo que se puede comprobar en las semanas siguientes, no en una explicación cerrada de la causa.
Aparte, entonces me sorprendió otra entrada de esa misma semana. Dicté: «no siento estrés, pero todo me irrita». El sistema no registró un estrés alto, porque los anclajes de las escalas (los definimos en el segundo artículo) distinguen esos estados, y en la reflexión apareció una formulación que desde entonces se me quedó grabada: la falta de sueño se come el colchón emocional. El estrés está bajo, la irritabilidad alta, y son métricas distintas con causas distintas. Ninguna app de salud con un formulario de «valora tu estrés del 1 al 10» me habría mostrado esa diferencia.
El workflow diario sin datos perfectos
El retrato realista de mi día con el diario:
- por la mañana, después del gimnasio: una captura del entrenamiento desde Hevy (o cualquier otro tracker, si usas otro stack);
- durante el día: nada, el sistema calla;
- por la noche, a las 21:00: el recordatorio, una nota de voz de 40 a 60 segundos, a veces el resumen de calorías de YAZIO o una app similar;
- después de la nota: una sola pregunta breve del bot, si me he dejado algo obligatorio.
El último punto importa más de lo que parece. Si no he dicho el peso, el bot pregunta exactamente una cosa: «No has mencionado el peso. ¿Te has pesado hoy?». No un cuestionario, no una lista de cinco campos que faltan, una sola pregunta sobre lo más importante. Si no respondo, el campo se queda vacío con la marca needs_review, y eso es lo correcto: un valor vacío es más honesto que uno inventado. Cuando al cabo de un mes dibujo el gráfico de peso, quiero ver los huecos en los datos, no los ceros que el modelo ha colocado amablemente.
Y no intentes dictar a la perfección. Mi nota de la noche es un flujo de conciencia: sobre el sueño, sobre el trabajo, sobre que el repartidor no me trajo el pedido y tuve que ir media hora a pie. Por cierto, esa nota se convirtió en mi ejemplo favorito de para qué sirve el texto libre en un diario: en vez de una queja, en la entrada quedó el reencuadre de «pero cerré los pasos del día y de camino llamé a la abuela». Las métricas no habrían captado eso. Un diario que solo guarda cifras pierde la mitad de la vida.
Cómo corregir los errores de reconocimiento
El primer diccionario apareció después de que el sistema llevara tres semanas seguidas convirtiendo YAZIO en ‘yazio’ y el peso muerto rumano en cualquier cosa menos en peso muerto rumano. El faster-whisper local falla de forma sistemática: los mismos nombres, ejercicios y términos — mal de la misma manera cada vez. La solución práctica es un diccionario de correcciones notes/known-asr-errors.md:
# Errores de reconocimiento conocidos
| Lo que se oyó | Término canónico | Contexto | Estado |
|---|---|---|---|
| peso muerto rumano / "muerto rumano" | peso muerto rumano | entrenamiento | verified |
| "yasi" / "yasio" | YAZIO | nutrición | verified |
| "jevi" / "jevy" | Hevy | entrenamiento | verified |
(Los ejemplos son sintéticos; tu diccionario se llenará con tus propios errores en las primeras dos semanas.)
Las reglas que distinguen un diccionario útil de uno peligroso:
- al diccionario solo entran correcciones que tú mismo has confirmado;
- la sustitución se aplica por contexto, no de forma global: una misma palabra «oída» puede significar cosas distintas en una conversación sobre entrenamiento y en una sobre personas;
- ante baja confianza, el skill hace una pregunta de aclaración en vez de corregir en silencio;
- el transcript en bruto queda intacto: la corrección vive en el resumen normalizado, y en el historial de Git se ve qué cambió y cuándo.
Con mi forma de hablar, un diccionario de errores recurrentes me dio más utilidad práctica que cambiar sin más a un modelo más grande. No es un benchmark universal: compara las opciones con tu propio conjunto de entradas cortas y no mires solo la accuracy, sino también la latency.
Capturas de entrenamientos: confía, pero verifica
La capa de visión aparte (en mi caso la API de OpenAI, a la que recurro cuando quiero) extrae de la captura de Hevy los ejercicios, las series, los pesos y la duración. Suena a magia, funciona como un becario: a veces sorprendentemente hábil, a veces ese que anotó el 60 como 80 con toda la confianza y se fue a casa. Los números en pantalla son el punto más débil del OCR: confundir un peso, perder un decimal, fusionar dos series en una.
Por eso las reglas son duras:
- el original de la captura se guarda siempre en
attachments/, junto a la entrada; - los datos extraídos reciben
source: ocryneeds_review: true; - los confirmo yo con una sola palabra en Telegram, y solo entonces el estado pasa a
verified; - si el servicio tiene una exportación estructurada oficial, normalmente conviene preferirla a la captura y comprobar aparte que los campos estén completos.
Fotos de documentos: máxima exactitud, mínima interpretación
La categoría más sensible: las fotos de documentos médicos y analíticas. Aquí el sistema hace deliberadamente poco: reconoce los valores, guarda el original, marca todo como needs_review y se detiene. Nada de interpretaciones del tipo «este indicador está elevado»: sin rangos de referencia, unidades de medida y contexto, eso es adivinar, y con ellos es trabajo del médico.
¿Para qué guardar entonces las analíticas en el diario?
Para, en la consulta con el especialista, abrir la cronología: aquí están los valores de medio año, aquí mi sueño y mis entrenamientos del mismo periodo, aquí mis preguntas. El diario prepara el material para la conversación con el médico, no lo sustituye. Antes de fotografiar, quita del encuadre los identificadores personales y recuerda los metadatos EXIF.
El resumen semanal: la capa de compresión
Treinta entradas diarias se le pueden pasar mecánicamente a un modelo de contexto grande, pero eso sale caro, mete ruido y dificulta verificar las fuentes. Por eso, entre el daily y el monthly hay una capa intermedia: el resumen semanal, que el reflection skill construye a partir de los siete archivos diarios.
Un buen resumen semanal está obligado a:
- calcular las medias solo sobre los valores rellenados y mostrar el denominador:
sueño: datos de 5/7 días; - no poner ceros en lugar de los huecos;
- enumerar los patrones recurrentes, no recontar cada día;
- referenciar entradas daily concretas como fuentes;
- proponer preguntas para observar, no conclusiones.
El denominador es el campo más infravalorado. «Sueño medio de 7,2 horas» a partir de dos días rellenados de siete no es estadística, es una casualidad con cara de seguridad.
El resumen semanal fue el primer momento en que el diario habló con algo más que la voz de un solo día. Un martes malo dejó de ser el centro del mundo y pasó a ser un punto entre siete. A veces confirmaba la sensación de una semana difícil; otras mostraba lo contrario: tres días habían sido normales, pero el viernes sonaba más fuerte en mi memoria que los demás.
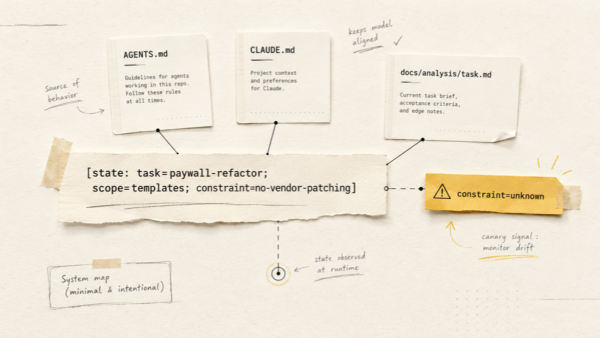
La reflexión mensual: análisis de diario con IA sin RAG inventado
Ahora viene la principal decepción que conviene vivir de antemano: el agente no recuerda tu vault. Lo comprobé específicamente una vez: le pedí al modelo que recapitulara las últimas semanas sin construir el contexto explícitamente primero. La respuesta parecía convincente — coherente, con detalles concretos y conclusiones. La mitad de los eventos mencionados sencillamente no existían en el diario. La persistent memory de Hermes y la búsqueda por sesiones no son un índice sobre tus archivos Markdown. Si simplemente le preguntas «analiza mi mes», el modelo responderá a partir de lo que por casualidad quedó en su memoria de conversaciones, y eso parecerá convincente y será basura.
Una reflexión mensual honesta es un montaje explícito del contexto. Tres modos de trabajo, de menos a más:
Sencillo: pedirle al reflection skill que lea los archivos de un rango de fechas. Funciona, pero para un mes de entradas se irán muchas llamadas a file tools y muchos tokens.
Recomendado: el helper script build-reflection-context.sh ejecuta una preparación determinista del contexto antes de cualquier IA: reúne daily/2026/06/*.md, parsea el YAML, calcula la cobertura de métricas, junta resúmenes compactos en un único archivo temporal reflection-context-2026-06.md, y ya es ese único artefacto el que analiza el modelo.
Escalable: la reflexión mensual lee de 4 a 5 resúmenes semanales más las métricas agregadas, y solo para comprobar hipótesis concretas abre archivos daily sueltos.
La regla de hierro para los tres modos: solo se admite citar como fuente un archivo que realmente entró en el contexto. Si en la reflexión pone «ver la entrada del 12 de junio», esa entrada fue leída, no «recordada». Y cada reflexión empieza con una cabecera honesta: rango, lista de archivos cargados, cobertura.
El agente no debe fingir que lo ha leído todo
En la petición se fijan el rango de fechas, la lista de archivos y los límites del análisis. Si parte del periodo no entró en el contexto, se indica de forma explícita en la respuesta: «análisis construido sobre 26 de los 30 días».
El prompt para analizar sueño, estrés y entrenamientos
Mi prompt de trabajo para la reflexión mensual, adáptalo a tu medida:
Analiza el contexto preparado para {mes}.
Formato de respuesta:
1. Cobertura de datos: cuántos días hay rellenados por cada métrica (X/30).
2. Evolución de sueño, energía, ánimo y estrés: solo sobre los días rellenados.
3. Vínculos recurrentes (por ejemplo: acostarse tarde → energía al día
siguiente), cada uno con enlaces a entradas daily concretas.
4. Para cada vínculo: explicaciones alternativas. Correlación no es causalidad.
5. Qué me prometí en la reflexión anterior y qué de eso se ve en los datos.
6. Un pequeño experimento para el mes que viene con un resultado medible.
7. Preguntas que conviene hacerle al especialista si el patrón se repite.
Prohibido: diagnósticos, consejos sobre medicamentos y suplementos, conclusiones
sobre causas sin matices, enlaces a entradas que no están en el contexto, medias
sin indicar el denominador.
El punto 6 es mi favorito. Justo de él nació la historia con la melatonina del primer artículo: la reflexión mostró un vínculo estable «melatonina por la noche → mañana pesada», el experimento fue trivial (dos semanas sin ella) y las mañanas se enderezaron. No un diagnóstico, no una conclusión médica: un experimento personal con un resultado medible, que luego comenté ya de forma concreta.
Y a veces la reflexión atrapa cosas que no son métricas en absoluto. Una vez en el resumen mensual apareció una cita de mi propia entrada de tres semanas antes: ‘cuando te acuestas entre las 22:00 y las 23:00, duermes bien; la energía de ayer tras una noche larga es suerte, no sistema’. No recordaba esa entrada en absoluto. Tuve que abrir el archivo original para confirmar que realmente la había escrito. El modelo no inventó la observación — la encontró y me la devolvió.
Paneles en Obsidian: Dataview sobre el frontmatter
Como las métricas viven en el YAML frontmatter, Dataview las convierte en una tabla mensual viva directamente en Obsidian:
TABLE sleep_hours, energy, mood, stress, training
FROM "daily/2026/06"
SORT date ASC
Un vistazo a la tabla basta para ver un clúster de malas noches o una semana en la que el estrés fue subiendo. El plugin Charts añade gráficas encima. Dos reglas de la práctica: visualiza los huecos, no los ocultes — un hueco en el gráfico de sueño también es información; y no construyas un ‘índice de salud IA general’ — un índice sintético crea una falsa precisión y destruye el valor de las métricas individuales.
Lo principal: el vault debe ser legible sin ningún plugin. Los dashboards son el glaseado, los datos son el pastel.
Cuánto cuesta en la práctica
En vez de cálculos — datos reales de OpenRouter durante dos meses de uso. Sinceramente, antes de empezar el proyecto esperaba ver costes un orden de magnitud mayores. Por eso estuve posponiendo la idea varios meses.
Mayo de 2026: todavía estaba experimentando con modelos, parte de las solicitudes iban a través de deepseek-v4-pro. Total del mes: $1.91, 880 solicitudes a pro y 159 a flash, más de 30 millones de tokens de entrada en total.
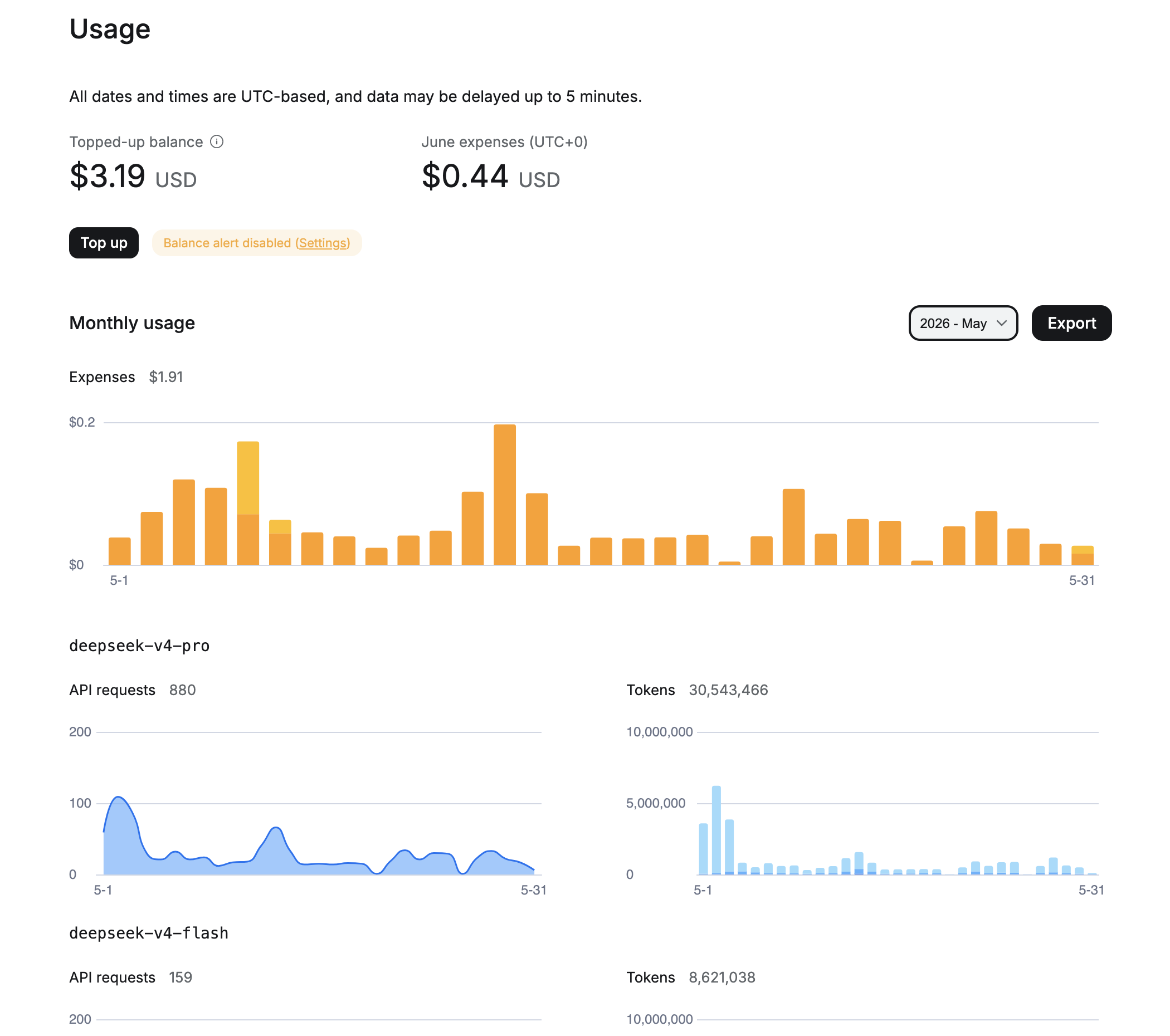
Junio de 2026 (primeros 13 días): cambié completamente a deepseek-v4-flash. 508 solicitudes, 26 millones de tokens, gastados $0.44. A ese ritmo, un mes completo sale alrededor de $1.
Estructura de costos por capa:
| Capa | Volumen mensual | Costo real |
|---|---|---|
| GitHub private repo | — | $0 (GitHub Free) |
| STT (faster-whisper local) | ~30 notas de voz | $0 por API, solo electricidad |
| DeepSeek vía OpenRouter | ~500 solicitudes, 26M+ tokens | ~$1/mes con flash |
| OpenAI vision (raramente) | Capturas y fotos de análisis | Partida variable separada; ponle un límite |
| Electricidad, portátil 24/7 | Funcionamiento continuo | Depende de tu tarifa y consumo |
Mayo salió más caro por los experimentos con el modelo pro. Flash cubre la normalización rutinaria de forma más económica y sin pérdida perceptible de calidad para las entradas del diario. Un modelo más potente solo tiene sentido para las reflexiones mensuales poco frecuentes — y solo sobre el mismo contexto ensamblado y verificable.
Privacidad y acceso a los datos: quién ve qué
Repito la tabla de los límites de confianza del primer artículo, ahora con decisiones sobre retention:
| Capa | Qué ve | Mi decisión |
|---|---|---|
| Telegram | Todos los mensajes al bot | Un compromiso consciente por comodidad |
| DeepSeek | Texto y derived text | No enviar documentos ni identificadores |
| OpenAI vision | Las imágenes enviadas | Límite de presupuesto, ningún documento con nombre y apellidos en el encuadre |
| GitHub | Todo el vault al hacer push | Private repo + 2FA; recordar: esto es control de acceso, no cifrado |
| Disco local | Todo, incluido el audio | Cifrado del disco, una estantería fuera del alcance del gato |
Un límite de confianza aparte es el teléfono. En el segundo artículo configuramos un espejo unidireccional del vault en iCloud para leerlo desde el iPhone, y tiene su precio: el contenido del diario aparece también en la nube de Apple. Si para ti eso es un participante de más, lee el diario solo en el escritorio o usa un único mecanismo de sincronización con un modelo de confianza que entiendas. La versión móvil del plugin Obsidian Git existe formalmente, pero es experimental y sin SSH, así que yo no me apoyaría en ella.
Decisiones sobre el almacenamiento de medios: las notas de voz las guardo con política short-retention (30 días, después solo queda el transcript), los originales de las capturas viven de forma permanente, las fotos de documentos son otra conversación con otra prudencia. Sea cual sea el modo que elijas, elígelo antes de empezar a operar y apúntalo en _system/retention-policy.md: limpiar binarios del historial de Git a posteriori es tarea para toda una tarde y con reescritura de la historia.
Y el procedimiento para el peor de los casos: si en el repositorio se cuela un secreto o un archivo con datos personales, borrarlo sin más no sirve (la historia lo recuerda todo). La secuencia: rotar el secreto → reescribir la historia → push forzado → revisar los clones. Analicé un incidente así en un proyecto de trabajo en el artículo sobre secretos subidos a Git por accidente, pero mejor que para ti quede en algo teórico: el secret scan antes de cada commit del segundo artículo existe precisamente por esto.
Cuándo conviene pasarse a modelos totalmente locales
¿Se puede llevar también la capa de texto de DeepSeek a tu propio portátil? Técnicamente sí: Hermes admite proveedores compatibles con OpenAI; el camino de Ollama hay que configurarlo mediante custom_providers y comprobarlo en tu versión. Entonces deja de salir al exterior hasta el texto. Los requisitos honestos:
- no hay un mínimo de contexto universal: los requisitos dependen de los skills elegidos, del volumen de archivos y del escenario de reflection;
- el hardware hay que elegirlo mediante una benchmark matrix; mi portátil de 2019 aguanta el Whisper local, pero para una LLM local decente ya le cuesta;
- en mis pruebas, los modelos locales pequeños fallaban más a menudo en la estructura, pero esto hay que repetirlo sobre un mismo synthetic fixture y publicar los resultados, no generalizar a partir de la impresión.
Y lo principal: una LLM local no hace que el sistema sea «totalmente privado». Telegram sigue viendo los mensajes, GitHub el vault. Pasarse a modelos locales tiene sentido de forma consciente, por una capa concreta, y no por la bonita palabra self-hosted en el titular.
Qué se rompe más a menudo
La tabla refleja los problemas operativos que aparecieron en los primeros meses de uso diario, y cubre todas las capas del sistema: el gateway de Telegram, el reconocimiento de voz, ambos proveedores de modelos, Git y el propio vault.
| Síntoma | Causa | Qué hacer |
|---|---|---|
| El bot calla | El daemon del gateway se cayó o no arrancó tras el reinicio | hermes gateway status, logs, systemd |
| El recordatorio no llegó / llegó a destiempo | Zona horaria o gateway parado | Una tarea de prueba a +2 minutos, timezone en la config |
| Las notas de voz tardan minutos en procesarse | Whisper en CPU o el modelo sobrecargado | Reducir el modelo, comprobar la GPU, medir la latencia |
| «No veo la imagen» | El proveedor de vision no está configurado o el modelo quedó obsoleto | Cotejar el model ID, la clave, los límites |
| Error del proveedor de texto | Se acabó el saldo o cambió el model ID | Saldo de DeepSeek, ID vigente |
| El push se cae | Claves SSH, token, red | ssh -T [email protected]; las entradas se acumulan en local, no se pierde nada |
| Entradas duplicadas en un mismo día | Lógica de upsert rota en el skill | Ruta canónica, la fixture del paso 12 del segundo artículo |
| El repositorio se hincha | Audio y fotos en Git | Política de retention, limpieza por reglas, no «a ojo» |
En los primeros meses, esta tabla cubrió la mayoría de mis fallos operativos y ayudaba a entender rápido por qué capa empezar el diagnóstico.
Lo que quedó después de los primeros meses
El diario funciona no porque el modelo sea inteligente, sino porque registrar el día se volvió más fácil que no registrarlo. El resto son consecuencias que entendí no a partir de la arquitectura, sino de episodios concretos.
Una vez salí del hábito durante una semana: un viaje de trabajo, se rompió la rutina, el bot mandaba recordatorios a nadie. Cuando volví y vi siete días vacíos en el vault, mi primer impulso fue rellenarlos de memoria a toro pasado. No lo hice. Dejé los huecos. Desde entonces soy mucho más tranquilo con los días que me salto: treinta entradas imperfectas son más útiles que siete perfectas, porque solo las imperfectas son reales.
La mayoría de mis problemas no vinieron del modelo sino de un esquema que rompí una vez. Cambié un campo del frontmatter sin migrar los archivos antiguos, y el resumen semanal empezó a calcular las estadísticas de manera diferente para días viejos y nuevos. Me di cuenta tres semanas después, cuando los números empezaron a parecer raros. A partir de ahí empecé a confiar mucho más en las reglas aburridas: nombres de archivo canónicos, esquema estricto, diccionario de correcciones — me dieron más que cualquier mejora del modelo.
Y esto: ya nunca toco las entradas en bruto. Todas las interpretaciones se pueden recalcular, el original perdido no se puede recuperar. Eso quedó claro el día que intenté ‘mejorar’ una entrada antigua y perdí el hilo de lo que realmente había pensado aquella tarde.
El diario no me hizo más sano por sí solo. Hizo visibles las consecuencias de las decisiones: la serie nocturna, la melatonina, tres malas noches antes del gimnasio. Las decisiones siguen siendo mías, y algunas las sigo tomando mal — pero ahora al menos de forma consciente.
El viejo portátil sigue igual en la estantería, el gato sigue igual de descontento, y yo, por primera vez en la vida, tengo un diario que ha sobrevivido al cuarto mes. Para alguien que abandonó todos los trackers en la tercera semana, esa es la mejor métrica posible.
Durante estos meses el agente no se convirtió en médico, psicólogo ni en un Jarvis que todo lo sabe. Al final resultó no ser un consejero inteligente. Más bien un sistema que no me deja olvidar lo que yo mismo ya me dije hace un mes. No vive el día por mí ni promete entenderme mejor de lo que me entiendo yo. Me ayuda a no perder hechos y a volver a mis propias palabras a tiempo, no un año después.
La serie termina donde empieza la práctica diaria: a las 21:00 el teléfono vibra, mantengo pulsado el botón de grabar y durante cuarenta segundos cuento cómo fue el día. La diferencia es que detrás de esa acción sencilla ya no hay otro servicio cerrado, sino una historia que me pertenece.
FAQ
¿Esto sustituye al médico o al psicólogo?
No. El sistema reúne observaciones y ayuda a preparar preguntas. Cualquier decisión sobre salud, con el especialista; cualquier síntoma preocupante, al médico directamente, no al diario.
¿El modelo no se pondrá a «diagnosticar» por su cuenta?
Lo hará si se lo permites: a los modelos les encanta sacar conclusiones rotundas. Por eso las restricciones están cosidas en el skill y en el prompt de la reflexión, no se sostienen sobre la buena fe. La sección «Prohibido» del prompt es su parte más importante.
¿Y si me salto días?
Nada. Saltarse un día es un dato, no un fracaso. Los resúmenes muestran la cobertura («sueño: 24/30 días») y el sistema nunca inventa valores para los días que faltan. Volver tras una pausa no da vergüenza: el bot no reprocha, simplemente continúa.
¿Se puede llevar el diario en dos idiomas?
Sí, Whisper se las apaña con el habla mezclada, y la normalización lo lleva todo a un mismo esquema. Yo dicto en ruso y planeo pasarme al inglés: el dictado diario es una práctica de conversación estupenda, y la estructura de las entradas no depende del idioma.
¿Por qué no dejarlo todo en manos de un único asistente potente con memoria?
Porque la memoria del asistente no son tus datos. Es el estado interno de un servicio ajeno: no puedes exportarla entera, comprobar qué hay dentro ni llevártela a otro proveedor. Los archivos Markdown de mi Git sobrevivirán a cualquier proveedor, a cualquier suscripción y a cualquier cambio de políticas: aunque mañana desaparezcan a la vez Hermes y DeepSeek, me quedaría un archivo completo de entradas que se lee con cualquier cosa. Además, la retention la decido yo: qué guardar, cuánto y cuándo borrarlo. Con la memoria del servicio, todas esas decisiones las toma el servicio.
¿Por dónde empiezo si tres artículos son demasiado?
Por un solo hábito: pon un recordatorio a las 21:00 y durante una semana respóndele con una nota de voz, aunque sea en tus «Mensajes guardados». Si el hábito prende, vuelve al segundo artículo y monta el sistema completo: tendrá algo que procesar.