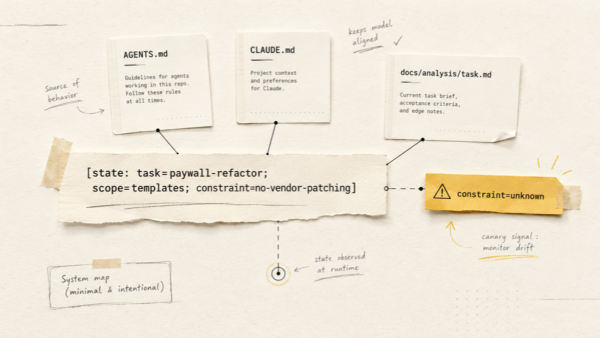
TL;DR
- Ценность AI-дневника появляется не в день установки, а через месяц, когда записи начинают складываться в паттерны: сон, стресс, тренировки, настроение.
- Агент не «помнит весь vault» автоматически: честная месячная рефлексия требует явно собрать контекст из файлов, и я показываю, как.
- Найденные связи — это гипотезы для наблюдения и вопросы специалисту, а не диагнозы.
В первый вечер после установки я несколько раз открыл папку с дневником, чтобы убедиться, что файл действительно появился. На второй день проверил commit. Через неделю поймал себя на том, что уже не открываю папку после каждой записи. А ещё через месяц не мог вспомнить, когда последний раз проверял логи вручную. Это был хороший знак: инструмент исчез из внимания и оставил только привычку.
В первой статье я рассказал, как старый игровой ноутбук стал домашним AI-сервером, во второй мы собрали систему с нуля. Эта статья о том, что происходит дальше, когда восторг от «оно работает!» проходит, а вечернее напоминание в 21:00 продолжает приходить: про ежедневную эксплуатацию и про анализ дневника с AI, когда записей накопилось достаточно.
Часть 3 из 3: эксплуатация, рефлексия и стоимость
Что меняется после первого месяца
Первую неделю вы играете с системой: шлёте голосовые, смотрите, как растёт vault, показываете боту скриншоты. К третьей неделе новизна выветривается, и остаётся голый механизм привычки: вибрация в 21:00, сорок секунд диктовки, подтверждение, всё. В этот момент главным качеством системы оказывается не интеллект модели, а отсутствие трения. Если бы мне приходилось открывать приложение и заполнять форму, я бы уже бросил.
Где-то после первого месяца я впервые начал задавать дневнику вопросы, а не просто складывать в него записи. Не «как я сегодня» — это я и так знаю, — а «почему вторую неделю подряд к четвергу я выжат». У одного дня нет ответа на этот вопрос. У тридцати — есть.
Покажу на составном примере из моей практики: детали изменены, чтобы не публиковать реальные записи. Три ночи подряд с прерывистым сном: среда, четверг, пятница. По отдельности каждая ночь выглядела случайностью: жара, поздний сериал, просто не спалось. А в субботу тренировка неожиданно далась тяжелее обычного. В моменте это выглядело как «плохой день в зале». В дневнике накопившийся недосып стал рабочей гипотезой, которую можно проверить по следующим неделям, а не готовым объяснением причины.
Отдельно меня тогда поразила другая запись той же недели. Я продиктовал: «стресса не чувствую, но всё бесит». Система не стала записывать высокий стресс, потому что якоря шкал (мы определили их во второй статье) различают эти состояния, и в рефлексии появилась формулировка, которую я с тех пор запомнил: недосып сжирает эмоциональный буфер. Стресс низкий, раздражительность высокая, и это разные метрики с разными причинами. Ни одно health-приложение с формой «оцените стресс от 1 до 10» этой разницы мне бы не показало.
Ежедневный workflow без идеальных данных
Реалистичная картина моего дня с дневником:
- утром после зала: скриншот тренировки из Hevy (или любого другого трекера, если вы используете другой стек);
- днём: ничего, система молчит;
- вечером в 21:00: напоминание, голосовая заметка на 40–60 секунд, иногда саммари калорий из YAZIO или аналогичного приложения;
- после заметки: одно короткое уточнение от бота, если я забыл обязательное.
Последний пункт важнее, чем кажется. Если я не назвал вес, бот спросит ровно одно: «Вес не озвучил. Взвешивался сегодня?» Не анкету, не список из пяти пропущенных полей, один вопрос про самое важное. Если я не ответил, поле останется пустым с пометкой needs_review, и это правильно: пустое значение честнее выдуманного. Когда через месяц я строю график веса, я хочу видеть дыры в данных, а не нули, которые модель вежливо подставила.
И не пытайтесь диктовать идеально. Моя вечерняя заметка — это поток сознания: про сон, про работу, про то, что доставщик не довёз заказ и пришлось идти полчаса пешком. Кстати, эта заметка превратилась в любимый пример того, зачем дневнику свободный текст: вместо жалобы в записи остался рефрейминг «зато шаги закрыл и бабушке по дороге позвонил». Метрики этого не поймали бы. Дневник, который хранит только цифры, теряет половину жизни.
Как исправлять ошибки распознавания
Первый словарь появился после того, как система третью неделю подряд превращала YAZIO в «язио», а румынскую тягу — во что угодно, кроме румынской тяги. Локальный faster-whisper ошибается систематически: одни и те же имена, упражнения и термины — одинаково неправильно. Практический способ — словарь notes/known-asr-errors.md:
# Известные ошибки распознавания
| Услышано | Каноничный термин | Контекст | Статус |
|---|---|---|---|
| румынская тяга / "румынский тяг" | румынская тяга | тренировка | verified |
| "язи" / "язио" | YAZIO | питание | verified |
| "хеви" / "хэви" | Hevy | тренировка | verified |
(Примеры синтетические, ваш словарь наполнится своими ошибками за первые две недели.)
Правила, которые отличают полезный словарь от опасного:
- в словарь попадают только исправления, которые вы подтвердили сами;
- замена применяется по контексту, не глобально: одно и то же «услышанное» слово в разговоре о тренировке и о людях может означать разное;
- при низкой уверенности skill задаёт уточняющий вопрос, а не молча исправляет;
- сырой transcript остаётся нетронутым: исправление живёт в нормализованной сводке, и в Git-истории видно, что когда поменялось.
На моей речи словарь повторяющихся ошибок дал больше практической пользы, чем простая замена модели на более крупную. Это не универсальный benchmark: сравните варианты на собственном наборе коротких записей и считайте не только accuracy, но и latency.
Скриншоты тренировок: доверяй, но проверяй
Отдельный vision-слой (у меня это OpenAI API, к которому я обращаюсь по желанию) извлекает из скриншота Hevy упражнения, подходы, веса и длительность. Звучит как магия, работает как стажёр: иногда удивительно толковый, иногда тот самый человек, который уверенно переписал 60 как 80 и пошёл домой. Цифры с экрана — самое слабое место OCR: перепутать вес, потерять десятичную точку, склеить два подхода в один.
Поэтому правила жёсткие:
- оригинал скриншота всегда сохраняется в
attachments/рядом с записью; - извлечённые данные получают
source: ocrиneeds_review: true; - подтверждаю я их одним словом в Telegram, и только после этого статус меняется на
verified; - если у сервиса есть официальный структурированный экспорт, обычно стоит предпочесть его скриншоту и отдельно проверить полноту полей.
Фото документов: максимум аккуратности, минимум интерпретации
Самая чувствительная категория: фото медицинских документов и анализов. Здесь система делает намеренно мало: распознаёт значения, сохраняет оригинал, помечает всё needs_review и останавливается. Никаких трактовок «этот показатель повышен»: без референсных диапазонов, единиц измерения и контекста это гадание, а с ними — работа врача.
Зачем тогда вообще хранить анализы в дневнике?
Чтобы на приёме у специалиста открыть хронологию: вот значения за полгода, вот мой сон и тренировки за тот же период, вот мои вопросы. Дневник готовит материал для разговора с врачом, а не заменяет его. Перед фотографированием уберите из кадра персональные идентификаторы и помните про EXIF-метаданные.
Недельная сводка: слой сжатия
Тридцать ежедневных записей можно механически передать модели с большим контекстом, но это дорого, шумно и затрудняет проверку источников. Поэтому между daily и monthly есть промежуточный слой: недельная сводка, которую reflection skill строит из семи дневных файлов.
Хорошая недельная сводка обязана:
- считать средние только по заполненным значениям и показывать знаменатель:
сон: данные за 5/7 дней; - не подставлять нули вместо пропусков;
- перечислять повторяющиеся паттерны, а не пересказывать каждый день;
- ссылаться на конкретные daily-записи как на источники;
- предлагать вопросы для наблюдения, не выводы.
Знаменатель — самое недооценённое поле. «Средний сон 7,2 часа» по двум заполненным дням из семи — это не статистика, это случайность с уверенным лицом.
Недельная сводка стала для меня первым моментом, когда дневник заговорил не голосом отдельного дня. Плохой вторник перестал быть центром мира и оказался одной точкой среди семи. Иногда это подтверждало ощущение тяжёлой недели, а иногда, наоборот, показывало: три дня были нормальными, просто пятница запомнилась громче остальных.
Месячная рефлексия: анализ дневника с AI без выдуманного RAG
Теперь о главном разочаровании, которое нужно прожить заранее: агент не помнит ваш vault. Я специально проверил это однажды: попросил модель пересказать последние несколько недель без явной сборки контекста. Ответ выглядел убедительно — связный, с конкретными деталями, с выводами. Половина упомянутых событий в дневнике просто не существовала. Persistent memory Hermes и поиск по сессиям — это не индекс по Markdown-файлам. Если просто спросить «проанализируй мой месяц», модель ответит на основе того, что случайно осталось в её памяти разговоров, и это будет выглядеть убедительно и быть мусором.
Честная месячная рефлексия — это явная сборка контекста. Три рабочих режима по нарастающей:
Простой: попросить reflection skill прочитать файлы за диапазон дат. Работает, но на месяц записей уйдёт много вызовов file tools и токенов.
Рекомендуемый: helper-скрипт build-reflection-context.sh запускает детерминированную подготовку контекста до всякого AI: собирает daily/2026/06/*.md, парсит YAML, считает покрытие метрик, складывает компактные сводки в один временный файл reflection-context-2026-06.md, и уже этот единственный артефакт анализирует модель.
Масштабируемый: месячная рефлексия читает 4–5 недельных сводок плюс агрегированные метрики, и только для проверки конкретных гипотез открывает отдельные daily-файлы.
Железное правило для всех трёх режимов: ссылка на источник допустима только на файл, который реально попал в контекст. Если в рефлексии написано «см. запись за 12 июня», эта запись была прочитана, а не «вспомнилась». И каждая рефлексия начинается с честной шапки: диапазон, список загруженных файлов, покрытие.
Агент не должен делать вид, что прочитал всё
В запросе фиксируются диапазон дат, список файлов и ограничения анализа. Если часть периода не вошла в контекст, это указывается в ответе явно: «анализ построен на 26 из 30 дней».
Промпт для анализа сна, стресса и тренировок
Мой рабочий промпт месячной рефлексии, адаптируйте под себя:
Проанализируй подготовленный контекст за {месяц}.
Формат ответа:
1. Покрытие данных: сколько дней заполнено по каждой метрике (X/30).
2. Динамика сна, энергии, настроения, стресса: только по заполненным дням.
3. Повторяющиеся связки (например: поздний отбой → энергия на следующий
день), каждая со ссылками на конкретные daily-записи.
4. Для каждой связки: альтернативные объяснения. Корреляция не причинность.
5. Что я обещал себе в прошлой рефлексии и что из этого видно в данных.
6. Один маленький эксперимент на следующий месяц с измеримым результатом.
7. Вопросы, которые стоит задать специалисту, если паттерн повторится.
Запрещено: диагнозы, советы по лекарствам и добавкам, выводы о причинах
без оговорок, ссылки на записи, которых нет в контексте, средние без
указания знаменателя.
Пункт 6 — мой любимый. Именно из него родилась история с мелатонином из первой статьи: рефлексия показала стабильную связку «мелатонин вечером → тяжёлое утро», эксперимент был тривиальным (две недели без него), и утра выровнялись. Не диагноз, не медицинский вывод: личный эксперимент с измеримым результатом, который я потом обсуждал уже предметно.
А иногда рефлексия ловит вещи, которые не метрики вовсе. Однажды в месячной сводке появилась цитата из моей же записи трёхнедельной давности: «когда ложишься в 10–11, высыпаешься качественно; вчерашняя энергия после позднего отбоя — везение, а не система». Я вообще не помнил ту запись. Пришлось открывать исходный файл и убеждаться, что правда сам это написал. Модель не придумала наблюдение — она его нашла и вернула мне.
Дашборды в Obsidian: Dataview поверх frontmatter
Раз метрики живут в YAML frontmatter, Dataview превращает их в живую таблицу месяца прямо в Obsidian:
TABLE sleep_hours, energy, mood, stress, training
FROM "daily/2026/06"
SORT date ASC
Одного взгляда на таблицу достаточно, чтобы увидеть кластер плохих ночей или неделю, где стресс полз вверх. Поверх этого плагин Charts строит графики. Два правила, которые я усвоил на практике: визуализируйте пропуски, не прячьте их — дыра в графике сна тоже информация; и не стройте «общий AI health score» — синтетический индекс создаёт ложную точность и убивает пользу отдельных метрик.
Главное: vault обязан оставаться читаемым без плагинов вообще. Дашборды — глазурь, данные — торт.
Сколько это стоит на практике
Вместо расчётов — реальные данные из OpenRouter за два месяца использования. Честно говоря, до начала проекта я ожидал увидеть расходы на порядок выше. Именно поэтому несколько месяцев откладывал идею.
Май 2026: я ещё экспериментировал с моделями, часть запросов шла через deepseek-v4-pro. Итого за месяц — $1.91, 880 запросов к pro и 159 к flash, суммарно 30+ миллионов входных токенов.
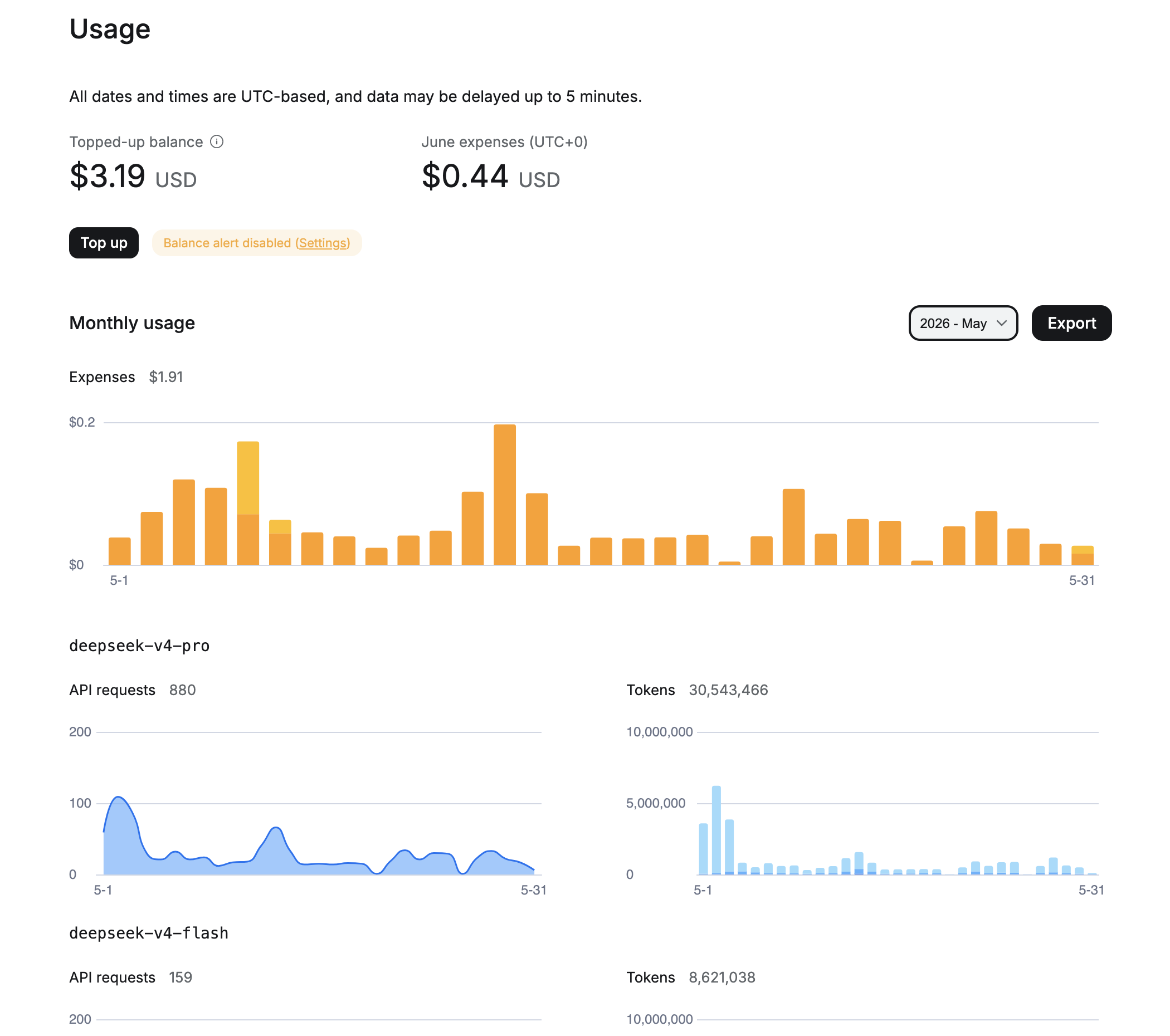
Июнь 2026 (первые 13 дней): полностью перешёл на deepseek-v4-flash. 508 запросов, 26 миллионов токенов, потрачено $0.44. При таком темпе выходит около $1 за полный месяц.
Структура расходов по слоям:
| Слой | Объём за месяц | Реальная стоимость |
|---|---|---|
| GitHub private repo | — | $0 (GitHub Free) |
| STT (локальный faster-whisper) | ~30 голосовых | $0 за API, только электричество |
| DeepSeek через OpenRouter | ~500 запросов, 26M+ токенов | ~$1/мес на flash |
| OpenAI vision (редко) | Скриншоты и фото анализов | Отдельная переменная статья; держите лимит |
| Электричество, ноутбук 24/7 | Круглосуточная работа | Зависит от тарифа и потребления железа |
Май оказался дороже из-за экспериментов с pro-моделью. Flash закрывает рутинную нормализацию дешевле и без заметной потери качества для дневниковых записей. Более сильную модель имеет смысл подключать только для редких месячных рефлексий — и только на том же собранном и проверяемом контексте.
Приватность и доступ к данным: кто что видит
Повторю таблицу границ доверия из первой статьи, теперь с решениями по retention:
| Слой | Что видит | Моё решение |
|---|---|---|
| Telegram | Все сообщения боту | Осознанный компромисс удобства |
| DeepSeek | Текст и derived text | Не отправлять документы и идентификаторы |
| OpenAI vision | Отправленные изображения | Лимит бюджета, никаких документов с ФИО в кадре |
| GitHub | Весь vault при push | Private repo + 2FA; помнить: это контроль доступа, не шифрование |
| Локальный диск | Всё, включая аудио | Шифрование диска, полка вне досягаемости кота |
Отдельная граница доверия — телефон. Во второй статье мы настроили одностороннее зеркало vault в iCloud для чтения с iPhone, и у него есть цена: содержимое дневника появляется ещё и в облаке Apple. Если для вас это лишний участник, читайте дневник только на десктопе или используйте один механизм синхронизации с понятной вам моделью доверия. Mobile-версия плагина Obsidian Git формально существует, но экспериментальна и без SSH, на неё я бы не полагался.
Решения по хранению медиа: голосовые я храню по политике short-retention (30 дней, потом остаётся только transcript), оригиналы скриншотов живут постоянно, фото документов — отдельный разговор с отдельной осторожностью. Какой бы режим вы ни выбрали, выберите его до начала эксплуатации и запишите в _system/retention-policy.md: задним числом вычищать бинарники из Git-истории — занятие на вечер и с перезаписью истории.
И процедура на случай худшего: если в репозиторий попал секрет или файл с персональными данными, простое удаление не помогает (история помнит всё). Последовательность: ротировать секрет → переписать историю → принудительный push → проверить клоны. Я разбирал такой инцидент на рабочем проекте в статье про случайно запушенные секреты, но лучше пусть она останется для вас теоретической: secret scan перед каждым коммитом из второй статьи существует именно поэтому.
Когда стоит уйти на полностью локальные модели
Можно ли вынести и текстовый слой с DeepSeek на свой ноутбук? Технически да: Hermes поддерживает OpenAI-compatible providers; Ollama path нужно настраивать через custom_providers и проверять на вашей версии. Тогда наружу перестаёт уходить даже текст. Честные требования:
- нет универсального минимума контекста: требования зависят от выбранных skills, объёма файлов и сценария reflection;
- железо нужно подбирать через benchmark matrix; мой ноутбук 2019 года тянет локальный Whisper, но для приличной локальной LLM ему уже тяжело;
- на моих пробах маленькие локальные модели чаще ошибались в структуре, но это нужно повторить на одном synthetic fixture и опубликовать результаты, а не обобщать по впечатлению.
И главное: локальная LLM не делает систему «полностью приватной». Telegram по-прежнему видит сообщения, GitHub — vault. Уходить в локальные модели имеет смысл осознанно, ради конкретного слоя, а не ради красивого слова self-hosted в заголовке.
Что ломается чаще всего
Таблица отражает эксплуатационные проблемы, которые проявились за первые месяцы ежедневного использования, и покрывает все слои системы: Telegram gateway, распознавание речи, оба model-провайдера, Git и сам vault.
| Симптом | Причина | Что делать |
|---|---|---|
| Бот молчит | Gateway daemon упал или не стартовал после ребута | hermes gateway status, логи, systemd |
| Напоминание не пришло / пришло не вовремя | Таймзона или остановленный gateway | Тестовая задача на +2 минуты, timezone в конфиге |
| Голосовые обрабатываются минутами | Whisper на CPU или модель перегружена | Уменьшить модель, проверить GPU, замерить латентность |
| «Не вижу изображение» | Vision-провайдер не настроен или модель устарела | Сверить model ID, ключ, лимиты |
| Ошибка провайдера текста | Кончился баланс или сменился model ID | Баланс DeepSeek, актуальный ID |
| Push отваливается | SSH-ключи, токен, сеть | ssh -T [email protected]; записи копятся локально, ничего не теряется |
| Дубликаты записей за день | Сломана upsert-логика в skill | Canonical путь, фикстура из шага 12 второй статьи |
| Репозиторий распух | Аудио и фото в Git | Retention policy, чистка по правилам, не «на глаз» |
За первые месяцы эта таблица покрыла большинство моих эксплуатационных сбоев и помогала быстро понять, с какого слоя начинать диагностику.
Что осталось после первых месяцев
Дневник работает не потому, что модель умная, а потому, что записать день стало дешевле, чем не записать. Остальное — следствия, которые я понял не из архитектуры, а из конкретных эпизодов.
Однажды я на неделю выпал из привычки: командировка, сбился режим, бот слал напоминания в пустоту. Когда вернулся и увидел семь пустых дней в vault, первый импульс был — заполнить их задним числом по памяти. Не сделал. Оставил дыры. С тех пор я гораздо спокойнее отношусь к пропускам: тридцать неидеальных записей полезнее семи идеальных, потому что только они реальные.
Больше всего проблем мне создала не модель, а однажды сломанная схема записи. Я поменял одно поле во frontmatter без миграции старых файлов, и недельная сводка начала считать статистику по-разному для старых и новых дней. Я заметил это только через три недели, когда цифры стали выглядеть странно. После этого я начал гораздо больше доверять скучным правилам: canonical имена файлов, жёсткая схема, словарь исправлений — они дали мне больше, чем любой апгрейд модели.
И ещё: сырые записи я теперь не трогаю никогда. Все интерпретации можно пересчитать, потерянный оригинал не вернуть. Это стало понятно в тот день, когда я попытался «улучшить» одну старую запись и потерял нить того, что я на самом деле думал в тот вечер.
Дневник не сделал меня здоровее сам по себе. Он сделал видимыми последствия решений: поздний сериал, мелатонин, три плохие ночи перед залом. Решения по-прежнему за мной, и часть из них я по-прежнему принимаю неправильно, но теперь хотя бы осознанно.
Старый ноутбук всё так же стоит на полке, кот всё так же недоволен, а у меня впервые в жизни дневник пережил четвёртый месяц. Для человека, который бросил все трекеры на третьей неделе, это лучшая метрика из возможных.
За эти месяцы агент не превратился в врача, психолога или всезнающего Джарвиса. В итоге он оказался не умным советчиком. Скорее системой, которая не даёт мне забыть то, что я сам себе уже говорил месяц назад. Он не проживает день за меня и не обещает понять меня лучше меня самого. Он помогает не потерять факты и вернуться к собственным словам вовремя, а не через год.
На этом серия заканчивается там же, где начинается ежедневная практика: в 21:00 телефон вибрирует, я зажимаю кнопку записи и сорок секунд рассказываю, как прошёл день. Разница лишь в том, что теперь за этим простым действием стоит не очередной закрытый сервис, а история, которая принадлежит мне.
FAQ
Это заменит врача или психолога?
Нет. Система собирает наблюдения и помогает готовить вопросы. Любые решения о здоровье — со специалистом, любые тревожные симптомы — к врачу напрямую, а не в дневник.
Модель не начнёт «диагностировать» сама?
Начнёт, если ей позволить: модели любят делать уверенные выводы. Поэтому ограничения зашиты в skill и в промпт рефлексии, а не держатся на честном слове. Раздел «Запрещено» в промпте — самая важная его часть.
Что если я пропускаю дни?
Ничего. Пропуск — это данные, а не провал. Сводки показывают покрытие («сон: 24/30 дней»), и система никогда не выдумывает значения за пропущенные дни. Возвращаться после перерыва не стыдно: бот не упрекает, он просто продолжает.
Можно ли вести дневник на двух языках?
Да, Whisper справляется со смешанной речью, а нормализация приводит всё к одной схеме. Я диктую на русском и планирую перейти на английский: ежедневная диктовка — отличная разговорная практика, а структура записей от языка не зависит.
Почему не отдать всё одному сильному ассистенту с памятью?
Потому что память ассистента — это не ваши данные. Это внутреннее состояние чужого сервиса: вы не можете его выгрузить целиком, проверить, что там лежит, или перенести к другому провайдеру. Markdown-файлы в моём Git переживут любого провайдера, любую подписку и любое изменение политик: даже если завтра исчезнут и Hermes, и DeepSeek, у меня останется полный архив записей, который читается чем угодно. Плюс retention решаю я: что хранить, сколько и когда удалить. С памятью сервиса все эти решения принимает сервис.
С чего начать, если три статьи — это слишком много?
С одной привычки: поставьте напоминание на 21:00 и неделю отвечайте на него голосовой заметкой хоть в «Сохранённые сообщения». Если привычка приживётся, возвращайтесь ко второй статье и собирайте полную систему: ей будет, что обрабатывать.