Un artículo para quienes ya han trabajado con la terminal
Este manual da por hecho un manejo básico de Ubuntu/Linux, Git y bots de Telegram. Si algo de esto te suena desconocido, no pasa nada: cualquier chat de IA te lo explicará paso a paso. Solo describe qué estás haciendo y pregúntale a ChatGPT, Gemini, Claude u otra herramienta que prefieras. Resuelven lo básico mejor que cualquier manual estático.
TL;DR
- El manual arranca con Ubuntu ya instalado: reserva varias horas para el sistema base y un tiempo aparte para el vault, los skills y la prueba de extremo a extremo.
- Montaremos un diario en Telegram sobre Hermes Agent con DeepSeek, reconocimiento de voz local y un repositorio Git privado.
- El texto, la voz y las imágenes siguen rutas distintas y verificables, y los originales en bruto siempre se guardan junto a la entrada final.
- Tras cada paso hay una comprobación, así que el error se localiza al instante y no cuando arrancas todo el sistema a la vez.
En el primer artículo conté cómo un viejo Xiaomi Mi Gaming Laptop se convirtió en un servidor doméstico de IA para el diario de bienestar, y por qué tras un mes con OpenClaw rehíce el sistema desde cero sobre Hermes Agent y DeepSeek. Ahora llega lo interesante: reproducir mi configuración desde cero. Este es el manual que a mí me habría gustado leer a principios de 2026, en lugar de ir armándolo a trozos.
Lo construí a propósito con el principio de «paso, comprobación, siguiente paso». Cuando monté la primera versión del sistema, mi gran error fue configurarlo todo de golpe y luego pasar dos tardes averiguando cuál de los seis componentes se quedaba mudo. No lo repitas: comprueba cada capa por separado.
El manual es largo, pero la ruta es sencilla. Primero daremos al agente una voz y un canal de comunicación, después le enseñaremos a convertir mensajes en tus archivos y, al final, añadiremos memoria, backup y hábito. Tras cada etapa, el sistema ya sabe hacer algo completo:
- Pasos 1–6: el bot responde a texto, voz e imágenes.
- Pasos 7–9: los mensajes se convierten en un archivo Markdown verificable con historial de cambios.
- Pasos 10–12: el diario se convierte en un sistema cotidiano, sobrevive reinicios y recuerda por sí mismo.
No hace falta terminarlo todo en una tarde. El mejor primer punto para parar es después de la prueba de voz del paso 5; el segundo, después del primer commit correcto del paso 9. Un sistema intermedio útil es mejor que una persona agotada intentando depurar vision, Git y cron a las dos de la mañana.
No copies los comandos antes de verificar las versiones
Hermes Agent evoluciona rápido. La auditoría actual se hizo en Hermes v0.12.0 (2026.4.30), commit 4f3766917 y Ubuntu 24.04.4 LTS; fecha de verificación: 2026-06-07. Para una versión más nueva, contrasta con el repositorio oficial.
Configuración de voz verificada
NVIDIA driver 535.309.01, GTX 1060 6 GB, CUDA 12.2, ffmpeg 6.1.1 y faster-whisper 1.2.1. El modelo medium funciona en CUDA con int8_float32; 22 segundos de audio de prueba se transcribieron en 2.17 segundos.
Parte 2 de 3: instalación desde cero
Qué vamos a montar

El mismo sistema en formato texto:
Telegram (solo tú, por allowlist)
│
▼
Hermes Gateway en la máquina Ubuntu (systemd, debe estar siempre activo)
├─ DeepSeek: normalización de texto de las entradas
├─ faster-whisper: reconocimiento local de mensajes de voz
├─ auxiliary vision: proveedor aparte para imágenes
├─ skills: wellbeing-journal + wellbeing-reflection
└─ cron: recordatorio cada noche a las 21:00
│
▼
Vault Markdown (compatible con Obsidian)
│
└─ git commit → repositorio privado de GitHub
En cuanto al hardware, sirve cualquier máquina que pueda funcionar de forma estable las 24 horas y cumpla los requisitos de los componentes elegidos. En mi caso es un portátil gaming de 2019 en una estantería de mi oficina doméstica: su GPU acelera el reconocimiento de voz, pero faster-whisper también funciona en CPU, solo que más despacio. Esta es la configuración que hay que fijar antes de publicar:
| Componente | El mío | Mínimo |
|---|---|---|
| SO | Ubuntu 24.04.4 LTS, kernel 6.17.0-22-generic, x86_64 | Ubuntu estable actual |
| CPU/RAM | Intel i7-8750H (6C/12T), 15 GiB de RAM / 10 GiB disponibles | Cualquier x86-64, 8 GB de RAM |
| GPU | GTX 1060 Mobile (6 GB) + Intel UHD 630; NVIDIA 535.309.01, CUDA 12.2 | No obligatoria (STT en modo CPU) |
| Disco | NVMe 154 GB, 84 GB libres (43%) | 20 GB libres |
| Hermes Agent | v0.12.0 (2026.4.30), commit 4f3766917 | La misma versión que en el artículo |
Antes de empezar: Ubuntu, cuentas y secretos
La instalación de Ubuntu la dejo fuera a propósito: ya hay instrucciones de sobra y de calidad, empieza por la documentación oficial de Ubuntu Server. El punto de partida del manual: un sistema limpio y actualizado, con acceso a internet y un usuario con sudo.
Prepara esto de antemano para no andar saltando entre pestañas después:
- una cuenta de Telegram (el bot se crea gratis a través de BotFather);
- una cuenta en la plataforma DeepSeek y un método de pago para la API key;
- una cuenta de OpenAI con un presupuesto pequeño para la capa de visión (opcional, sin ella funcionan el texto y la voz);
- una cuenta de GitHub con la autenticación en dos pasos activada;
- Obsidian en el escritorio para revisar las entradas (opcional, el vault sigue siendo Markdown corriente).
Regla de los secretos para todo el manual
Las claves de API y los tokens viven solo en ~/.hermes/.env y en el gestor de contraseñas. Nunca: ni en el vault, ni en el repositorio Git, ni en capturas. Todas las claves de este artículo son placeholders, no intentes usarlas.
Y una última cosa: decide dónde va a estar la máquina. Mi portátil vive en una estantería de pared por encima de la altura de la cabeza. El motivo es prosaico: el gato. Si tienes animales, niños de cuatro años u otras fuentes de caos, piénsalo antes de que el sistema forme parte de tu rutina diaria.
Paso 1. Preparar Ubuntu
Actualizamos el sistema e instalamos las dependencias básicas:
sudo apt update && sudo apt upgrade -y
sudo apt install -y git curl ffmpeg python3
ffmpeg hará falta para convertir los mensajes de voz de Telegram antes del reconocimiento, y Python para Hermes y los scripts auxiliares. En la auditoría del 2026-06-07 python3, git, node y rg estaban disponibles, pero ffmpeg y un uv standalone no se encontraron en el PATH. Si uv --version no responde, instálalo siguiendo las instrucciones oficiales de astral.sh/uv o usa el entorno de Hermes en ~/.hermes/hermes-agent/venv/.
Comprueba enseguida la zona horaria: de ella depende que el recordatorio nocturno llegue realmente por la noche.
timedatectl
# si hace falta:
sudo timedatectl set-timezone Europe/Madrid
Si vas a usar GPU para el reconocimiento de voz, comprueba que el sistema ve la tarjeta:
nvidia-smi # verificado: GTX 1060 6 GB, driver 535.309.01, CUDA 12.2
Comprobación: timedatectl muestra tu zona horaria, ffmpeg -version responde sin errores.
Si no funciona: no sigas adelante. Cada paso siguiente se apoya en este.
Paso 2. Instalación de Hermes Agent
La instalación oficial se hace con un solo comando. Pero antes de ejecutar cualquier curl | bash de internet, incluido este, abre la URL en el navegador y revisa el script: tienes que entender qué vas a ejecutar en la máquina que va a guardar tu diario personal.
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
echo $SHELL # averiguamos el shell activo
source ~/.bashrc # bash es el predeterminado en Ubuntu
# source ~/.zshrc # si te has pasado a zsh
Después, diagnóstico:
hermes doctor
hermes --version
En este punto las cosas no fueron bien a la primera. Tras la instalación, el comando hermes sencillamente no se encontraba en el PATH, aunque el instalador había terminado sin errores. El problema resultó ser trivial: el nuevo shell no había vuelto a leer su configuración. source ~/.bashrc — y todo funcionó. Pero esos minutos los recuerdo cada vez que veo source ~/.bashrc en un manual y pienso “obvio, lo salto”.
Comprobación: hermes doctor no muestra problemas críticos, hermes --version imprime la versión. Anótala: es tu punto de referencia para cualquier troubleshooting.
Resultado esperado: los critical checks pasan; en la auditoría del 2026-06-07 hermes doctor mostró PASS en las comprobaciones críticas y minor OAuth warnings.
Si no funciona: casi siempre es cosa del PATH: reinicia la terminal o vuelve a hacer source del archivo de configuración de tu shell.
Paso 3. Conectar DeepSeek para el texto
DeepSeek en esta arquitectura es el caballo de batalla. Al principio quería conectar un modelo más potente — ya tenía suscripciones pagadas. Pero cuando calculé cuántos tokens consume la rutina diaria con heartbeat, check-in y tareas cron, quedó claro que los modelos estrella para un diario nocturno son la solución al problema equivocado. DeepSeek normaliza las entradas rápido y barato, y el modelo potente se puede conectar de forma puntual para la reflexión mensual.
Crea una API key en el panel de la plataforma oficial de DeepSeek y lanza la selección interactiva de modelo:
hermes model
Elige DeepSeek en la lista de proveedores e introduce la clave cuando Hermes te la pida: la guardará en ~/.hermes/.env como DEEPSEEK_API_KEY. No edites los archivos a mano mientras la CLI sepa hacerlo por sí sola. Si la selección interactiva no aparece (por ejemplo, en una sesión headless sin TTY), en la versión verificada se usan las claves model.default, model.provider y model.base_url en ~/.hermes/config.yaml.
El model ID vigente en la fecha de verificación: deepseek-v4-flash. Precios actuales para esta verificación: cache hit $0.0028, cache miss $0.14, output $0.28 por 1M tokens (verificado: 2026-06-07, antes de configurar abre la página oficial de precios).
Smoke test sin salir de la terminal:
hermes -z "Responde con una sola palabra: ¿funciona?"
Comprobación: el agente responde, y en la respuesta se ve que se ha usado el modelo DeepSeek.
Si no funciona: comprueba que la clave está escrita en ~/.hermes/.env, que la cuenta de DeepSeek tiene saldo positivo y que el model ID no está obsoleto (pasa).
Paso 4. Crear el bot de Telegram y echarle el candado
Primero creamos el bot a través de la herramienta oficial de Telegram:
- Abre Telegram y busca @BotFather (marca azul, el oficial).
- Envía el comando
/newbot. - BotFather te pedirá el nombre del bot (el que se muestra, por ejemplo «My Wellbeing Journal») y un username (tiene que terminar en
_bot, por ejemplomy_wellbeing_bot). - A cambio recibirás un HTTP API token del tipo
7123456789:AAF.... Guárdalo en el gestor de contraseñas enseguida: se muestra una sola vez, después solo se puede reiniciar con/revoke.
Después necesitarás tu user ID numérico. La forma más sencilla de averiguarlo: escríbele a @userinfobot en Telegram y te responderá con tu ID en una sola línea. Anótalo junto al token. El path actual de Hermes: pasar por hermes gateway setup o enviar /whoami al bot por DM en Telegram tras conectarlo.
Conectamos el gateway:
hermes gateway setup
El asistente de configuración te pedirá el token del bot. Lo más importante de este paso: la allowlist. En la configuración final debe aparecer:
# ~/.hermes/.env
TELEGRAM_ALLOWED_USERS=123456789 # tu ID numérico, placeholder
La mayor parte del tiempo no la dediqué a los modelos ni a Ubuntu, sino a entender la diferencia entre chat ID, user ID y la allowlist. Son tres configuraciones distintas que es fácil confundir, y yo las confundí:
| Ajuste | De qué se encarga |
|---|---|
TELEGRAM_ALLOWED_USERS | Quién tiene derecho a hablar con el bot, en general. Autorización. |
TELEGRAM_HOME_CHANNEL | Adónde entrega el bot los mensajes por defecto (por ejemplo, los recordatorios de cron). Dirección de entrega. |
--deliver telegram:<chat id> | Dirección de entrega explícita de una tarea cron concreta. |
Indicar el chat ID de entrega no basta para cerrar el bot: sin allowlist sigue abierto para cualquiera que lo encuentre por su nombre. Un diario personal con la puerta abierta es la peor combinación posible.
Arrancamos y comprobamos:
hermes gateway # foreground, para la primera comprobación
# luego, para funcionamiento permanente:
hermes gateway install # instala el servicio systemd
hermes gateway status
Comprobación: escríbele «hola» al bot desde tu cuenta: debe responder. Pídele a alguien que le escriba desde otra cuenta: el bot debe quedarse callado.
Si no funciona: mira los logs (~/.hermes/logs/gateway.log); lo más habitual es que el problema esté en el token o en que en la allowlist hayas puesto un username en lugar del ID numérico.
Paso 5. faster-whisper local para los mensajes de voz
Los mensajes de voz son la interfaz principal del sistema. El propio mensaje pasa por Telegram, pero después de la entrega Hermes lo reconoce con faster-whisper local, sin mandar el audio a otro proveedor de STT en la nube. La dependencia de voz se instala así:
cd ~/.hermes/hermes-agent
uv pip install -e ".[voice]"
El comando se ejecuta en el entorno que gestiona la instalación de Hermes. En el sistema verificado, el virtualenv está en ~/.hermes/hermes-agent/venv/. Si no encuentras un uv standalone en el PATH, primero recupera/instala uv o usa el documented update/install path de Hermes para esta versión.
Config STT real a 2026-06-07:
stt:
enabled: true
provider: local
local:
model: medium
language: ''
Esta config elige el modelo multilingüe faster-whisper medium. En el runtime verificado se usa faster-whisper 1.2.1, device cuda y compute type int8_float32.
Después viene la elección del tamaño del modelo, y aquí hay una bifurcación honesta:
- base: rápido incluso en CPU, para notas cortas del día a día en un solo idioma suele bastar;
- medium: notablemente más preciso con habla mezclada y términos, pero pide GPU o paciencia;
- configuración verificada:
medium, CUDA en una GTX 1060 6 GB,int8_float32; 22 segundos de audio se procesan en 2.17 segundos.
Consejo sacado del uso real: no vayas directo a por un modelo grande. En un par de semanas verás qué palabras se reconocen mal de forma estable, y un diccionario contextual de correcciones (aparecerá en el tercer artículo) lo arregla más barato que pasarse a un modelo pesado.
Comprobación: mándale al bot un mensaje de voz de 20-30 segundos en tu idioma. En la prueba de control, 22 segundos de audio se transcribieron en 2.17 segundos en la GPU.
Si no funciona: comprueba ffmpeg, la importación de faster_whisper en el venv de Hermes, nvidia-smi, la RAM/VRAM libre y los logs del gateway.
STT en la nube como fallback
Hermes tiene alternativas de STT en la nube (Groq, OpenAI, Mistral). Son más rápidas en hardware flojo, pero entonces cada mensaje de voz se va a un tercero. Para un diario de bienestar lo considero inaceptable por defecto: elige la nube de forma consciente, no porque sea más cómodo.
Paso 6. Una capa de visión aparte para las imágenes
Recuerdo cómo es la ruta de las imágenes: en esta configuración DeepSeek se encarga del texto, y las capturas de entrenamientos de Hevy y las fotos de documentos pasan por una capa de visión auxiliar aparte. Es un proveedor aparte con un presupuesto aparte; en mi caso es la API de OpenAI con un límite de gasto pequeño. El paso es opcional: conecto la visión cuando quiero y la uso bastante poco, así que si no necesitas imágenes puedes saltártelo y vivir tranquilo con el texto y la voz.
# ~/.hermes/config.yaml
auxiliary:
vision:
provider: openai
model: auto # hay que confirmar el resolved model en los logs antes de publicar
# ~/.hermes/.env
OPENAI_API_KEY=sk-placeholder
Si nunca has trabajado con la API de OpenAI: la clave se crea en la sección API keys, y el límite de gasto se ajusta en las secciones de billing/usage del panel. Pon un tope mensual estricto desde el principio: las peticiones de visión son más caras que las de texto, vas a mandar capturas todos los días, y el tope convierte la posible sorpresa, en el peor caso, en un «el bot dejó de ver imágenes hasta fin de mes».
Comprobación: mándale al bot cualquier captura sin datos personales, por ejemplo una ventana de terminal. El bot debe describir qué hay en la imagen.
Si no funciona: contrasta el nombre del modelo con la documentación actual de OpenAI, comprueba la clave y los logs. El síntoma típico de una capa de visión sin conectar: el bot responde bien al texto, pero a la imagen responde «no veo la imagen» o con un error del proveedor. El síntoma de un model ID obsoleto: un error tipo model not found en los logs del gateway.
Aquí puedes parar por esta noche
Si el texto, la voz y una imagen de prueba funcionan, ya tienes un agente de Telegram operativo. Los pasos siguientes no lo hacen más inteligente — le dan memoria. El vault, Git y el cron pueden esperar hasta la próxima tarde.
Paso 7. Crear el vault Markdown
La primera versión del archivo tenía un aspecto mucho más correcto. Había una carpeta inbox, categorías anidadas, niveles numerados e incluso una carpeta para “sin clasificar”. Al cabo de un mes entendí que gastaba más tiempo manteniendo la estructura que escribiendo entradas. Por eso el vault actual parece casi aburrido — y ese es exactamente su sentido:
wellbeing-journal/
├── daily/YYYY/MM/YYYY-MM-DD.md # una entrada por día, nombre canónico
├── weekly/YYYY/YYYY-Www.md # resúmenes semanales
├── monthly/YYYY/YYYY-MM.md # reflexiones mensuales
├── notes/
│ ├── terminology.md # tus términos: ejercicios, suplementos
│ ├── measurements-history.md # historial de mediciones
│ └── known-asr-errors.md # diccionario de correcciones de reconocimiento
├── documents/
│ ├── lab-results/YYYY/MM/
│ └── reports/YYYY/MM/
├── attachments/YYYY/MM/YYYY-MM-DD/ # originales de capturas y fotos
├── audio/ # mensajes de voz, según retention policy
├── templates/
│ ├── daily.md
│ ├── weekly.md
│ ├── monthly.md
│ └── lab-result.md
├── scripts/
│ ├── validate-entry.sh
│ ├── build-reflection-context.sh
│ ├── sync-to-mobile.sh
│ └── commit-entry.sh
├── _system/
│ ├── schema.md # contrato del frontmatter
│ ├── scales.md # definiciones de las escalas 1-10
│ ├── safety.md # límites médicos del skill
│ └── retention-policy.md
├── dashboards/
├── JOURNAL_GUIDE.md
├── .gitignore
└── .obsidian/
El contrato clave del sistema: Markdown para la persona, YAML para la automatización. El cuerpo de la entrada sigue siendo texto libre, y todo lo que luego van a leer los dashboards y las reflexiones vive estrictamente en el frontmatter:
---
date: 2026-06-06
schema_version: 1
sleep_hours: 7.5
sleep_quality: 4
energy: 3
mood: 4
stress: 2
pain: 0
training: strength
symptoms: []
medications_changed: false
source: telegram
needs_review: false
---
Tres reglas cuya infracción me costó cara corregir después en mi propio archivo:
- un valor desconocido se queda como
nullo vacío; el modelo nunca pone un 0 en lugar de «no lo dijo»; - la fecha del frontmatter está obligada a coincidir con el nombre del archivo;
- las escalas (estado de ánimo, energía, estrés) están definidas en
_system/scales.mdcon anclajes, y la autoevaluación del usuario siempre pesa más que la «valoración por el tono del mensaje».
Los anclajes de escala protegen contra la deriva semántica. Sin ellos, el modelo acabará decidiendo que “todo me fastidia” significa estrés alto, cuando para ti significa energía baja. Mis anclajes de trabajo de _system/scales.md:
## Ánimo (mood)
- 1–2 — deprimido, tristeza | 3–4 — irritado, todo molesta
- 5–6 — plano, neutral (¡esto es normal!) | 7–8 — animado | 9–10 — euforia
## Energía (energy)
- 1–2 — apagado | 3–4 — pereza, bajón de tarde
- 5–6 — modo trabajo | 7–8 — con energía | 9–10 — hiperactivo
## Estrés (stress)
- 1–2 — calma | 3–4 — fondo leve
- 5–6 — presión notable | 7–8 — ansiedad, mal sueño | 9–10 — crisis
Nota importante sobre el ánimo: 5–6 es la norma, no “malo”. Y el consejo principal para las puntuaciones: no pienses. El primer número que te venga a la cabeza es el correcto. Cuanto más deliberas entre un cuatro y un cinco, menos significa esa cifra.
Comprobación: crea la estructura, deja un archivo daily de prueba según la plantilla y abre la carpeta en Obsidian: el vault debe abrirse sin errores y sin plugins de la comunidad obligatorios.
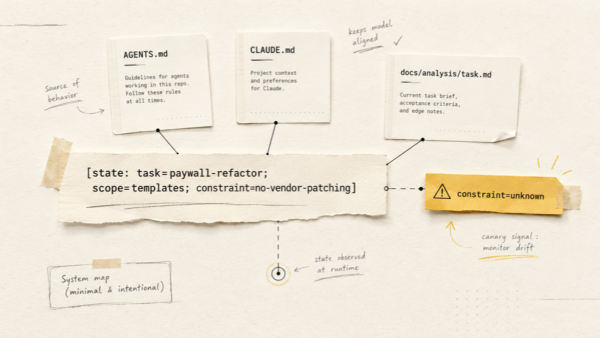
Paso 8. Skills: un núcleo sin monolito
Los skills de Hermes viven en ~/.hermes/skills/, cada uno en su carpeta con un SKILL.md obligatorio. Mi primera versión del skill del diario era un único archivo de cientos de líneas, y comprobar su comportamiento era imposible. La composición que funciona: dos skills, cada uno con un núcleo corto y references extraídas aparte.
~/.hermes/skills/personal/wellbeing-journal/
├── SKILL.md # núcleo corto: flow y reglas de enrutamiento
├── references/
│ ├── schema.md # copia del contrato del frontmatter
│ ├── input-text-voice.md # procesamiento de texto y mensajes de voz
│ ├── input-images.md # procesamiento de imágenes y OCR
│ ├── safety.md # límites médicos
│ ├── provenance.md # reglas de procedencia
│ └── git-workflow.md # reglas de los commits
├── templates/
│ └── confirmation.md # plantilla de confirmación en Telegram
└── scripts/
├── validate_entry.py
├── upsert_daily.py
└── safe_commit.sh
~/.hermes/skills/personal/wellbeing-reflection/
├── SKILL.md # solo análisis semanal/mensual
├── references/
│ ├── reflection-rubric.md
│ └── medical-boundaries.md
└── scripts/
└── build-reflection-context.sh
El núcleo del skill del diario al completo. Para Hermes v0.12.0 hace falta un YAML frontmatter con los campos obligatorios name y description:
# wellbeing-journal
Llevas el diario de bienestar personal del usuario. Eres un asistente
de registro, no un médico: no diagnosticas, no recetas ni retiras
tratamientos, no interpretas síntomas urgentes. Reglas completas: references/safety.md.
## Formatos de entrada
- Texto: nota del día o respuesta al check-in nocturno.
- Voz: el transcript ya lo prepara el sistema. Reglas: references/input-text-voice.md.
- Imágenes: capturas de entrenamientos y fotos de documentos. Reglas: references/input-images.md.
## Flujo principal
1. Determina la fecha de la entrada. Si la fecha es ambigua, haz UNA pregunta de aclaración.
2. Extrae solo los hechos comunicados de forma explícita. No inventes valores.
Una métrica que falta se queda como null, nunca 0.
3. Normaliza las escalas según _system/scales.md. La autoevaluación del usuario pesa más
que tu valoración del tono.
4. Reúne los campos OBLIGATORIOS que falten en una sola pregunta compacta
(«¿Sueño / energía / ánimo / estrés en cifras en una línea?»).
No preguntes por los campos opcionales.
5. Escribe en la ruta canónica daily/YYYY/MM/YYYY-MM-DD.md mediante scripts/upsert_daily.py:
reprocesar la misma fecha actualiza el archivo, no crea uno nuevo.
6. Guarda la entrada en bruto (transcript, texto) en la sección Raw, aparte del Summary.
Nunca sobrescribas Raw con tu interpretación.
7. Marca los datos de imágenes con needs_review: true y source: ocr.
8. Ejecuta scripts/validate_entry.py. Si la validación falla, avisa del error,
no hagas commit.
9. Commit solo a través de scripts/safe_commit.sh (que además hace secret scan).
10. Envía una confirmación corta según templates/confirmation.md: qué se ha guardado,
qué campos se han rellenado, qué queda como needs_review.
## Prohibido
- Conclusiones médicas, diagnósticos, consejos sobre medicamentos y dosis.
- Interpretar valores de laboratorio sin units ni reference ranges.
- Git push ante la sospecha de secretos en la entrada.
- Crear archivos con sufijos -2, FINAL, evening y cualquier variante
del nombre canónico.
- Copiar logs del sistema, errores de proveedores y la salida de cron al diario:
son eventos operativos, no observaciones de bienestar.
Los listados completos de references, plantillas y scripts auxiliares conviene sacarlos a un fixture aparte después de la verificación final de los comandos. Hasta que exista ese repositorio, el artículo no debe prometer un enlace listo. El reflection skill lo veremos en detalle en el tercer artículo; para la instalación basta con crear su esqueleto.
Comprobación: mándale al bot el texto «Dormí 7 horas, energía 4, ánimo 4, estrés 2, no entrené». Debe aparecer un archivo daily/2026/06/2026-06-06.md con el frontmatter relleno y tu texto en la sección Raw. Manda una aclaración «corrección: dormí 6 horas»: el archivo debe actualizarse, no debe aparecer un segundo archivo.
Si no funciona: comprueba que el agente ve el skill (hermes skills list) y que en el SKILL.md están indicadas las rutas correctas al vault.
Paso 9. Repositorio Git privado
Git resuelve aquí dos cosas: backup e historial de correcciones. Cuando dentro de un mes corrijas un error de reconocimiento en una entrada antigua, será el git history el que muestre qué cambió y cuándo.
cd ~/wellbeing-journal
git init
git add .
git commit -m "Initial vault structure"
Crea en GitHub un repositorio vacío y privado, y conéctalo a través de una clave SSH o del credential helper del sistema. No uses un token en texto plano en la remote URL: se quedará en la config para siempre.
git remote add origin [email protected]:youruser/your-private-journal.git # placeholder
git push -u origin main
.gitignore obligatorio antes del primer commit con sentido:
.obsidian/workspace*
.trash/
*.tmp
.DS_Store
Y una regla que conviene aprender antes, no después: borrar un archivo en el siguiente commit no lo elimina del historial. Si al repositorio llega una vez un token o la foto de un documento con datos personales, el simple «borrar y hacer commit» no sirve: hará falta reescribir el historial y rotar el secreto. Yo pasé por esto en un proyecto de trabajo y lo conté en un artículo aparte, cómo limpiamos secretos subidos a Git por accidente: mejor leerlo antes de que haga falta.
Por eso en safe_commit.sh, antes de cada commit, se ejecuta un secret scan primitivo pero funcional. Un esqueleto fácil de ampliar con tus propios patrones:
#!/usr/bin/env bash
# safe_commit.sh — commit solo después de comprobar si hay secretos
set -euo pipefail
cd "$(dirname "$0")/.."
# Patrones: claves DeepSeek/OpenAI, token del bot de Telegram, genérico
PATTERNS='sk-[A-Za-z0-9]{16,}|DEEPSEEK_API_KEY=|OPENAI_API_KEY=|[0-9]{8,10}:[A-Za-z0-9_-]{30,}'
if git diff --cached --diff-filter=ACM -U0 | grep -qE "$PATTERNS"; then
echo "DETENIDO: en los cambios staged se ha encontrado un posible secreto." >&2
exit 1
fi
git commit -m "${1:-Update journal entry}"
git push || echo "Push aplazado: las entradas se han guardado en local."
La versión completa, con validación del esquema de las entradas, solo hay que publicarla junto con un fixture verificado. Hasta entonces, en el artículo queda un ejemplo mínimo y seguro y una checklist antes del push.
Comprobación: haz un push de prueba, luego clona el repositorio en otro directorio y asegúrate de que el vault se abre desde el clon recién hecho. Esto es a la vez una comprobación del backup y un ensayo de la restauración.
Si no funciona: casi siempre son las claves SSH. ssh -T [email protected] mostrará si estás autorizado.
En este punto ya puedes apagarlo y usarlo
Los archivos están en su sitio, el historial de cambios existe, el restore está probado. Todo lo que hay debajo son mejoras, no pasos obligatorios.
Paso 10. Obsidian y la lectura desde el móvil
En el escritorio todo es sencillo: abre ~/wellbeing-journal como vault. Con el móvil la cosa se complica, y aquí te doy un consejo honesto en lugar de uno bonito: no conectes dos mecanismos de sincronización a la misma carpeta. Git e iCloud/Obsidian Sync escribiendo a la vez en un mismo vault tarde o temprano provocan un conflicto en el archivo más valioso.
Mi opción de trabajo: el vault canónico vive en Git en el servidor, y al iPhone se va un espejo unidireccional de solo lectura (scripts/sync-to-mobile.sh hace un rsync --delete a la carpeta de iCloud, excluyendo .git). Leo el diario desde el móvil, pero escribo en él solo a través del bot. Las ediciones desde el móvil en el espejo se sobrescribirán con la siguiente sincronización, y es una limitación consciente, no un bug.
Alternativas: Obsidian Sync oficial como único mecanismo (sin Git) o modo solo escritorio. La implementación móvil de Obsidian Git es experimental y no admite SSH; yo no apostaría por ella.
Comprobación: lanza sync-to-mobile.sh primero con --dry-run y revisa la lista de acciones, luego la ejecución real y la comprobación en el móvil.
Paso 11. Recordatorio a las 21:00
El toque final que convierte un conjunto de componentes en un hábito. Primero fija la zona horaria en la config de Hermes:
# ~/.hermes/config.yaml
timezone: "Europe/Madrid"
Un valor vacío significa la hora local del servidor; uno explícito siempre es más fiable. Luego, antes de fiarte de la sintaxis de cualquier artículo, incluido el mío:
hermes cron create --help
Creamos la tarea:
hermes cron create "0 21 * * *"
"Recuérdame rellenar el wellbeing check-in nocturno: sueño, energía, ánimo, estrés, síntomas, entrenamiento y eventos importantes del día. No saques conclusiones médicas."
--name "Evening wellbeing check-in"
--deliver telegram
Las tareas cron las ejecuta el daemon del gateway. No basta con crear una tarea — el gateway debe estar funcionando continuamente, que es exactamente para lo que lo instalamos como servicio systemd en el paso 4.
Y no te creas la programación a la primera. Crea una tarea de prueba para los próximos dos minutos y comprueba la hora real de entrega:
hermes cron create '2m' 'Envía exactamente una palabra: TEST' --name 'STT Smoke Test Confirm' --deliver telegram
hermes cron list
# después de comprobar:
hermes cron remove <job_id>
Mi primer recordatorio llegó a tiempo, pero solo porque hice esta prueba de dos minutos y pillé el desfase de antemano. Un detalle importante aquí: la eliminación funciona solo por job ID, no por el nombre de la tarea. Una hora depurando la zona horaria por la noche el día del lanzamiento o dos minutos de prueba: la elección está clara.
Comprobación: la tarea de prueba llegó a Telegram a la hora local esperada; hermes cron list muestra la tarea permanente a las 21:00.
Si no funciona: comprueba hermes gateway status, el timezone en la config y TELEGRAM_HOME_CHANNEL: un --deliver telegram a secas entrega justo ahí.
Paso 12. Prueba de extremo a extremo
Ahora ejecutamos el sistema entero, como un día de la vida real:
| Prueba | Resultado esperado | Dónde buscar el error |
|---|---|---|
| Check-in de texto | Una entrada daily y un commit | Gateway, skill, permisos del vault |
| Mensaje de voz | Raw audio, transcript y entrada estructurada de la misma fecha | Whisper, GPU/CPU, códec, ffmpeg |
| Captura de entrenamiento | Attachment guardado, campos del entrenamiento rellenos, fuente: ocr | Vision API, límites, MIME |
| Foto demo de un documento | Datos extraídos, pero marcados como needs_review: true | Capa de visión, reglas del skill |
| Reenvío | Actualización de la entrada sin duplicado y sin archivos con sufijos | Lógica de upsert, ruta canónica |
| Reinicio de la máquina | El gateway se levantó solo, el bot responde | Servicio systemd |
| Push con el Wi-Fi apagado | Entrada guardada en local, el push se pone al día más tarde, sin pérdida de datos | git-workflow en el skill |
La prueba de extremo a extremo lleva unos veinte minutos, y son los mejores veinte minutos de toda la instalación: después de ellos confías en el sistema lo suficiente como para entregarle un check-in nocturno de verdad.
Test de extremo a extremo superado
El bot acepta todos los formatos, actualiza una sola entrada, sobrevive a un reinicio y no pierde datos cuando el Wi-Fi está apagado. Puedes enviar tu primer check-in vespertino real.
Checklist final
- [ ]
TELEGRAM_ALLOWED_USERScontiene solo tu ID numérico, el bot calla ante extraños. - [ ] Todos los secretos en
~/.hermes/.envy el gestor de contraseñas, ninguno en el vault, Git ni capturas. - [ ] Zona horaria comprobada con una tarea de prueba real, no por suposición.
- [ ] El mensaje de voz se reconoce en local, latencia medida.
- [ ] Capa de visión configurada aparte, con un límite de gasto en la cuenta del proveedor.
- [ ] El reenvío de la misma fecha actualiza la entrada, no se crean duplicados.
- [ ] El raw input se guarda aparte del resumen normalizado.
- [ ] Repositorio privado, 2FA activada, un fresh clone se abre en Obsidian.
- [ ] El gateway sobrevive al reinicio de la máquina sin arranque manual.
Cómo actualizar Hermes Agent
Hermes evoluciona rápido, y un día necesitarás actualizar. Para la versión verificada, el comando de actualización es: hermes update, después obligatoriamente hermes doctor y hermes --version, comprobar hermes gateway status y un mensaje de prueba al bot. Tras actualizaciones grandes, contrasta el formato del encabezado de los skills: los breaking changes en proyectos que evolucionan rápido pasan.
Errores frecuentes
Token en la remote URL
Un token en texto plano en la dirección del repositorio se queda en la config y el historial para siempre. Solo clave SSH o credential helper.
Esperar que DeepSeek lea solo la imagen
En esta arquitectura el texto y las imágenes van por rutas distintas. DeepSeek se encarga del texto, y las imágenes pasan por una capa de visión auxiliar aparte: un paso de configuración aparte y un presupuesto aparte (en mi caso, un límite pequeño de la API de OpenAI).
Chat ID en lugar de allowlist
La dirección de entrega y el derecho a hablar con el bot son ajustes distintos. Sin TELEGRAM_ALLOWED_USERS el bot está abierto para todos.
Cron sin comprobar la zona horaria
Primero una tarea de prueba a los dos minutos, luego la programación permanente. Si no, las «21:00» acabarán siendo la hora del servidor y no la tuya.
Dos mecanismos de sync en un vault
Git más iCloud escribiendo a la vez en una carpeta provocarán un conflicto algún día. Una única fuente canónica, lo demás: espejo unidireccional.
Configurarlo todo de golpe y depurar después
Seis capas configuradas sin comprobaciones intermedias se depuran más despacio de lo que se instalan. Paso, comprobación, siguiente paso.
Qué viene después
El momento más extraño llega después de toda la instalación. Has estado horas con Ubuntu, claves, systemd y Git, y entonces le envías al bot tu primer mensaje de voz. Un par de segundos después aparece un archivo Markdown, y de pronto entiendes que era para eso para lo que se montó todo.
El sistema está montado y comprobado, pero lo interesante empieza después: la primera semana de entradas, los primeros errores de reconocimiento, los primeros resúmenes semanales y la pregunta «¿y ahora qué hago con todo esto?». De eso va el tercer artículo: el uso diario, la reflexión mensual honesta sin un RAG inventado, los dashboards en Obsidian, el coste real por capas y la privacidad. Ahí contaré justamente cómo el diario pilló mi combinación «melatonina → mañana rota», que yo mismo no notaba.
FAQ
¿Hace falta GPU?
No. faster-whisper funciona en CPU, solo que el reconocimiento lleva más tiempo. La GPU puede reducir notablemente la latencia; la latencia real hay que medirla con el modelo y el hardware elegidos.
¿Sirve una Raspberry Pi o un VPS?
La ruta de texto: sí. El reconocimiento de voz local en un ARM flojo será un suplicio, y en un VPS se suma la cuestión de confiar en el hostinger que tiene tu diario. Un viejo portátil x86: el término medio ideal.
¿Se puede en Windows o macOS?
Hermes admite otras plataformas, pero el happy path de este manual se limita a Ubuntu. Los comandos solo se pueden considerar reproducibles tras rellenar el bloque de versiones y la prueba de extremo a extremo. En macOS la lógica general es la misma, las diferencias empiezan en la instalación de dependencias y el arranque automático.
¿Cuánto tiempo lleva la instalación?
A mí personalmente la migración desde el sistema anterior me llevó varias horas, pero no es un benchmark universal. Para una primera vez es razonable reservar una sesión para el sistema base y otra aparte para el vault, los skills y la prueba de extremo a extremo, sobre todo si toca pelearse con la GPU, systemd o el delivery de Telegram.
¿Dónde se guardan físicamente mis datos y quién tiene acceso a ellos?
Las entradas y los originales viven en tu máquina y en un repositorio privado de GitHub. Por el camino los ven Telegram (incluidos los mensajes de voz), DeepSeek (texto) y el proveedor de visión (imágenes). El faster-whisper local evita un envío adicional del audio a un proveedor de STT, pero no saca a Telegram de la cadena. Un private repo es control de acceso, no cifrado: el análisis detallado de los límites de confianza está en el tercer artículo.
¿Cuánto cuesta DeepSeek al mes con un uso diario?
El coste de la capa de texto depende del número real de tokens y de las tarifas vigentes: el cached input, el uncached input y el output se cuentan por separado. La visión se paga aparte y, con imágenes frecuentes, puede convertirse en una parte notable del presupuesto. La fórmula de cálculo y una instantánea de precios con fecha las doy en el tercer artículo; antes de configurar, contrasta con la página oficial de precios de DeepSeek.