Большинство статей про AI-агентов либо продают их как магию, либо предсказывают, что разработчиков заменят уже завтра. После работы с Claude Code, Codex, Cursor и Gemini-инструментами Google на реальных проектах моя точка зрения скучнее и, как мне кажется, полезнее: AI-агент — это очень быстрый junior-разработчик, который не устаёт, не чувствует контекст и которого ни в коем случае нельзя оставлять один на один с продакшеном. Из этой одной идеи и вырастает весь рабочий процесс ниже.
Это гайд для тех, кто уже прошёл стадию «вау, оно написало функцию» и хочет получить повторяемый процесс: правила, инструменты, шаблоны промптов, этапы и то, что я по-прежнему делаю руками.
Обновлено в мае 2026: AI-агенты для разработки уже не выглядят как умный autocomplete. Codex живёт в CLI, IDE, облаке и мобильном сценарии, Claude Code обзавёлся зрелой моделью permissions и hooks, Cursor активно развивает background agents и AI-review pull requests, Google продвигает Gemini CLI, Gemini Code Assist и Jules, а MCP стал общим интеграционным слоем. Возможностей стало больше, но цена ошибки тоже выросла.
Почему вопрос безопасности важнее вопроса продуктивности
Один показательный кейс. В 2025 году The Guardian описал ситуацию, где AI-агент удалил production-базу данных компании, потому что выполнил инструкцию буквально. Это не редкий баг. Это нормальное поведение агента: он читает инструкцию и выполняет её максимально прямо, без понимания бизнес-контекста.
У меня есть своя, менее эффектная версия этой истории. На старте я попросил агента «почистить лишние файлы в проекте». Он с радостью удалил папку, которую я ещё не закоммитил, вместе с половиной дня работы. Агент сделал ровно то, что я попросил. Ошибка была моя: формулировка, scope, окружение, отсутствие подтверждения. Как только принимаешь, что это структурный режим отказа, а не редкая случайность, остальной процесс перестаёт казаться параноидальным и начинает казаться разумным.
Поэтому основной вопрос сегодня звучит не «как использовать AI», а «как использовать его безопасно». Стоит принять эту рамку, и весь остальной процесс становится логичным.

Пять правил, которые я не нарушаю
Они не зависят от модели или инструмента и одинаково работают для Claude Code, Codex, Cursor, Gemini и того, что выйдет завтра.
- Минимум прав, всегда. Агент получает ровно те ключи и доступы, которые нужны для текущей задачи. Никаких admin-токенов «на всякий случай». Для GitHub — fine-grained токен на один репозиторий с минимальным набором прав. Для базы — read-only пользователь, если запись не цель задачи. Для облака — временные креды с истечением.
- Наблюдайте за тем, что он делает, особенно в первый раз. Современные CLI по умолчанию просят подтверждение для shell-команд. Не отключайте. День, когда вы это сделаете, — день, когда что-нибудь сломается.
- Деструктивные операции не делегируются. Миграции базы, удаления, force push, изменения инфраструктуры — это всё я делаю руками. Агент может подготовить команду и объяснить, что она делает. Enter жму я.
- Коммиты и push — зона ответственности разработчика. Агент может предложить сообщение и подготовить файлы. Diff я читаю построчно перед
git commit, аgit push— всегда вручную. - Можно доверять задаче, но не её последствиям.
Если запомните только последнюю строчку — этого уже достаточно.
Первичная настройка проекта
Большинство современных инструментов работают по схожей схеме: ставите CLI (например, Claude Code или OpenAI Codex), указываете на репозиторий, и агент индексирует проект. Дальше основную работу делают три конфигурационные сущности.
Что изменилось в workflow с AI-агентами к маю 2026
Инструменты ушли от формата «чат с репозиторием» к маленькой операционной модели разработки. В материале OpenAI о безопасном запуске Codex хорошо сформулирован принцип: держать агента в технических границах, быстро разрешать низкорисковые действия и явно подтверждать высокорисковые. Я применяю тот же подход локально.
В Claude Code settings и hooks уже позволяют кодировать правила проекта, а не надеяться только на строчку в промпте. Background agents в Cursor полезны, когда работа может идти в удалённой ветке и потом проходить review, но они требуют аккуратных прав к репозиторию: агент умеет сам запускать команды в удалённой среде. У Google картина разделена между Gemini CLI, Gemini Code Assist внутри IDE и Jules для асинхронных coding tasks, связанных с GitHub. MCP-интеграции дают GitHub, браузерные проверки, логи и документацию, но каждый MCP-сервер — это ещё одна поверхность возможностей. Относитесь к нему как к зависимости с доступами.
Моё правило на 2026 год простое: чем автономнее агент, тем явнее должны быть границы. Автономность без scoped credentials, review-gates и воспроизводимых проверок — это не продуктивность, а скорость, приложенная к неопределённости.
1. CLAUDE.md — долгосрочная память агента
Самый важный первый шаг — инициализация. В Claude Code команда /init создаёт файл CLAUDE.md в корне репозитория. Этот файл подгружается в каждый разговор. Здесь вы рассказываете агенту, как проект устроен на самом деле.
Никогда не принимайте сгенерированный файл как есть. Скелет нормальный, но в деталях он почти всегда ошибается: придумывает команды, упускает соглашения, оптимистично описывает «чистоту» кодовой базы. Читайте построчно и исправляйте.
Хороший CLAUDE.md отвечает на:
- Что это за проект — одним абзацем, понятным человеку со стороны.
- Стек и версии: PHP 8.3, Node 20, версия фреймворка, всё нестандартное.
- Команды: как запустить, протестировать, отлинтить, задеплоить. Настоящие команды, которые работают сегодня.
- Архитектура: где что лежит, почему, какие слои. Два-три абзаца, не роман.
- Соглашения: именование, структура файлов, то, что вы поправили бы на ревью.
- Запретные зоны: файлы и папки, которые нельзя трогать, даже если рядом что-то «не так».
- Процедура деплоя, особенно ручные шаги.
Пишите так, как онбордили бы нового инженера. Агент работает по тому же принципу.
1b. Один AGENTS.md на всех агентов
Маленький, но очень полезный приём, как только у вас больше одного инструмента. Вместо того чтобы поддерживать отдельные CLAUDE.md, GEMINI.md и конфиги Codex с одним и тем же содержимым, держите единый AGENTS.md в корне репозитория как источник истины, а каждый файл под конкретный инструмент пусть просто ссылается на него:
# CLAUDE.md
@AGENTS.mdТо же для GEMINI.md и любого другого агента, который поддерживает ссылки на файлы. Правишь один файл — изменение видят все агенты. Никакого «обновил Claude, забыл обновить Gemini» и тихого расхождения между инструментами.
2. Настройки и разрешения
Современные CLI позволяют разделить команды на «запускать без вопросов» и «всегда спрашивать подтверждение». Используйте это. У меня read-only команды (git status, git diff, ls, cat) разрешены тихо, всё остальное — с подтверждением. Пять секунд на нажатие y — самая дешёвая страховка в вашем процессе.
3. Хуки для жёстких ограничений
Всё, что должно соблюдаться, а не просто проситься в промпте, идёт в хуки. Например, pre-commit, запрещающий push в main, или проверка, что определённые файлы не редактируются. Агент не «забудет» хук. Инструкцию — легко.
MCP-инструменты, которые я подключаю
MCP (Model Context Protocol) — стандарт, через который агент общается с внешними системами. У меня есть три постоянные интеграции и несколько, которых я сознательно избегаю.
GitHub MCP
Официальный GitHub MCP позволяет агенту создавать issues, читать PR, оставлять комментарии и запускать запросы для код-ревью и поиска кода. Я использую fine-grained токен на один репозиторий, ровно с теми правами, которые нужны под задачу. Никаких личных токенов с админ-доступом на всю организацию и никакого общего токена между проектами.
Laravel Boost
Для Laravel-бэкендов Laravel Boost открывает агенту маршруты, логи, SQL-запросы и Artisan-команды. Сильно сокращает переписку «покажи, где определён этот маршрут». Самое полезное — инспекция маршрутов: агент отвечает «какой контроллер обрабатывает этот URL» без grep.
Chrome DevTools MCP
Chrome DevTools MCP даёт агенту настоящий браузер: переходы, клики, формы, Network, консоль, скриншоты и Lighthouse. Это и есть основа лёгкого end-to-end тестирования без полноценного Playwright-сьюта.
Что я сознательно не даю агенту
Креды боевой базы. Что угодно с биллингом. SSH-ключи на живые сервера. Личный GitHub-токен. Логика простая: если одна неверная команда создаёт инцидент — агент этого не получает.
Мой процесс из пяти этапов
После того как агент настроен, каждая нетривиальная задача проходит одни и те же пять этапов. Смысл этой структуры — не в бюрократии. Она удерживает агента в тех частях работы, где он быстр, и подальше от тех, где он опасен.

Этап 1. Создание задачи
Раньше написать нормальный GitHub issue занимало 15 минут. Сейчас я формулирую задачу одним абзацем и прошу агента оформить её с описанием и метками. Пример:
«Создай GitHub issue: добавить backend-поддержку блока Usage Statistics на странице Subscription для пользователей браузерного расширения. Повтори логику, реализованную для SDK. Ответ должен содержать
wordsLimit,wordsCount,wordsLeft,percentageUsed,percentageLeft. Сошлись на контроллер SDK. Предложи acceptance criteria».
Получаю структурированный issue с контекстом, acceptance criteria, ссылками на файлы и нужными метками — за минуту. Перед сохранением всё равно перечитываю. Секрет в том, чтобы загрузить промпт конкретикой: назвать существующую реализацию, имена полей, конкретную страницу. Тогда агент не придумывает детали.
Этап 2. Письменный анализ задачи
До любого кода прошу агента изучить текущую реализацию, найти связанные файлы, перечислить ограничения и предложить два-три подхода с компромиссами. Ключевой момент — попросить сохранить результат как markdown-файл в репозитории, например docs/analysis/usage-stats.md.
Почему это важнее, чем кажется:
- У агента ограниченная рабочая память. Файл — это устойчивый контекст, который он может перечитать, не пересматривая половину кодовой базы.
- Завтра вы откроете его и быстро вспомните, о чём была речь, даже если контекст разговора пропал.
- Запись заставляет агента занять конкретную позицию. Расплывчатые ответы превращаются в конкретные, как только их надо зафиксировать.
- Если анализ неверный — вы ловите это сейчас, когда стоимость правки = комментарий, а не переписать всё.
Промпт, который я переиспользую:
«Перед написанием кода проанализируй задачу. Прочитай связанные файлы, найди швы, куда должно лечь изменение, перечисли ограничения (форма данных, авторизация, кэширование, i18n), предложи 2–3 подхода с компромиссами. Сохрани анализ в
docs/analysis/<task-slug>.md. На этом этапе не редактируй production-код».
Фраза «не редактируй production-код» важна. Без неё агенты охотно начинают «попутно чинить» во время анализа.
Более сильный промпт для анализа в 2026
«Проанализируй эту задачу как маленький implementation RFC. Прочитай релевантные файлы, перечисли конкретные файлы, которые ты смотрел, опиши data contracts, границы permissions, cache/i18n-риски и тесты, которые уже покрывают соседнее поведение. Предложи два подхода: самый маленький безопасный change и более чистое долгосрочное решение. Сохрани результат в
docs/analysis/<task-slug>.md. Production-код не редактируй».
Фраза про просмотренные файлы не декоративная. Она помогает ловить выдуманный анализ: агент должен показать, на какие факты он опирался.
Этап 3. План, потом реализация
Из анализа агент составляет пронумерованный план: что менять, в каком файле, в каком порядке. Это самый дешёвый момент, чтобы поймать неверные допущения. Поправить пункт плана бесплатно. Переписать наполовину готовую фичу — нет.
В большинстве агентных CLI есть отдельный «plan mode», который запрещает правки до согласования. Используйте. Это разница между 30-секундной дискуссией и откатом уверенно неверного diff.
В зависимости от риска я либо реализую план сам, используя агента как умное автодополнение, либо позволяю ему идти по шагам с ревью каждого diff. Грубое правило:
- Чистые рефакторы, скэффолд, тесты, бойлерплейт: агент пишет, я делаю групповое ревью.
- Новая бизнес-логика: агент пишет, я читаю каждую строку.
- Безопасность, авторизация, платежи, миграции: я пишу, агент ревьюит.
Этап 4. Тестирование в реальном браузере
С Chrome DevTools MCP агент может:
- Открыть локальный сайт
- Зарегистрировать тестового пользователя или войти под фикстурой
- Пройти затронутый пользовательский сценарий
- Следить за консолью и Network
- Сделать скриншот в точке сбоя
Хорошо работает чек-лист в промпте: «открой страницу Subscription, убедись, что новый блок рендерится, что wordsLeft совпадает с ответом API, что в Network нет 4xx и 5xx, сделай скриншот и отчитайся».
Чего это не ловит: UX-проблемы, доступность, медленная отрисовка, «работает, но ощущается странно». После агента я всегда прохожусь по фиче сам. Браузерная автоматизация — сеть против регрессий, а не показатель качества.
Этап 5. PR и коммиты
Коммиты — за мной. Агент может предложить сообщение, но индексирую файлы, читаю diff и делаю commit я. То же с git push.
А вот описание PR — отличный кандидат на делегирование. Промпт, который стабильно даёт нормальный результат:
«Напиши описание PR для текущей ветки. Включи: абзац-резюме, маркированный список пользовательски-видимых изменений, test plan, заметки о миграциях/rollout, ссылку на issue. Анализируй diff против
main, не выдумывай изменений, которых нет в diff».
«Не выдумывай» — рабочая фраза. Без неё агенты добавляют в описание PR правдоподобные изменения, которых на самом деле в коде нет.
Где реально появляется выигрыш по времени
Если честно мерить, агент почти никогда не экономит время «написанием кода». Сам код — небольшая доля работы. Экономия рождается вокруг:
- Создание issue: с 15 минут до примерно 1.
- Анализ незнакомой кодовой базы: с часов чтения до 5–10 минут структурированного вывода.
- Описание PR: с 10–15 минут до 1.
- Базовое регрессионное тестирование: большой кусок повторяющихся кликов исчезает.
- Бойлерплейт (CRUD, формы, фикстуры, повторяющиеся миграции): минуты вместо десятков минут.
- Чтение документации ради одной детали: агент читает, вы спрашиваете. Эта экономия тихо побеждает остальные.
В этом и есть реальная ценность: агент убирает поддерживающую работу вокруг инженерии, и больше дня уходит на решения, которые должен принимать человек. Экономия в час в день — реальна. Обещание «агент написал всё за меня» — в основном маркетинг.
Чеклист перед тем, как дать агенту задачу
- Я могу описать ожидаемый результат одним абзацем? Если нет, сначала уточняю задачу сам.
- Blast radius маленький? CSS-правка, test fixture или локальный скрипт подходят агенту. Payments, auth и migrations — нет.
- У агента только нужный доступ? По умолчанию read-only, запись только там, где она правда нужна.
- Есть способ проверить результат? Тест, браузерный сценарий, WP-CLI команда, screenshot, review diff.
- Попытку можно выбросить? Если нет — использую branch, worktree или делаю задачу руками.
Чеклист намеренно скучный. Именно скучный процесс позволяет пользоваться интересными инструментами, не превращая production в эксперимент.
Неочевидные уроки, которые пришлось получить на себе
Контекстная деградация — реальная штука
Чем длиннее разговор, тем хуже агент. После долгой сессии правок, отступлений и неудачных попыток модель начинает противоречить ранним решениям, забывать ограничения из system prompt и возвращать только что починенные баги. Когда это чувствуется — не дави. Правильный ход: начать новый разговор, ткнуть в файл анализа из этапа 2 и продолжить оттуда. Это одна из самых высоко-эффективных привычек в работе с агентами.
Агенты переусердствуют на размытых задачах
Попросите «починить» — получите фикс плюс переименование, плюс «маленькую чистку», плюс рефакторинг функции, которую агент счёл уродливой. Всегда задавайте границу явно: «измени только функцию X. Не рефактори ничего другого. Не переименовывай. Не двигай файлы». Звучит невротически до тех пор, пока вы не потратите час на откаты несвязанных изменений.
Тесты пишутся с агентом, но не для агента
Дать агенту написать тест к фиче, которую он только что написал, — классическая ловушка. Тест зафиксирует его собственное недопонимание вместо требования. Либо напишите тест сами и пусть агент сделает его зелёным, либо пишите тест в отдельной сессии. Вторая модель спорит лучше, чем та же самая.
git worktree — для параллельной работы агента
Если хочется попробовать рискованный подход, не блокируя основную ветку, запускайте агента в отдельном git worktree. Изолированная рабочая директория на отдельной ветке, которую можно выкинуть целиком. Безопаснее, чем stash и переключение веток под агентом, который может не понять, что контекст сменился.
Не токены — основной бюджет
Все боятся стоимости токенов. На практике на серьёзном платном тарифе предельная стоимость задачи — копейки по сравнению с часом разработчика. Настоящий бюджет — ваше внимание. Ревью и подтверждения и есть дефицитный ресурс, а не API-токены. Это меняет, какие оптимизации имеют смысл.
Двойное ревью лучше самопроверки, но не настолько, насколько хочется
Связка из двух агентов: один пишет, другой ревьюит. Claude реализует, ChatGPT критикует, или наоборот. Работает удивительно хорошо: вторая модель видит слепые пятна первой. Но не панацея. Две модели уверенно согласятся с одним и тем же неверным ответом, особенно когда им не хватает проектного контекста. Финальное решение всё равно за человеком.
Ловушка уверенности
Агенты почти никогда не звучат неуверенно. Они объяснят неработающий подход с той же спокойной интонацией, что и работающий. Не «правильно ли это» (ответ — да), а «что должно быть истинным, чтобы это было ошибкой, и как это проверить».
Типичные ошибки новичков
- Давать агенту admin-доступы. Всегда ограничивайте scope. Read-only токена хватает в 80% случаев.
- Пропускать вычитку
CLAUDE.md. Мусор на входе — мусор в каждой следующей задаче. - Принимать код без чтения diff. Агент с радостью удалит тесты, чтобы они «прошли», или закомментирует упавший ассерт.
- Разрешать
git pushи продакшен-команды. Сэкономленное нажатие не стоит риска. - Просить «фикс» без этапа анализа. Получите правдоподобный код, который лечит симптом, а не причину.
- Затягивать одну сессию на часы. Лучше начать заново. Стоимость re-priming меньше, чем стоимость действий на испорченном контексте.
- Верить отчётам агента на слово. «Все тесты прошли» требует верификации. И «всё реализовано» — тоже.
Конкретный пример из реальной работы
Свежая задача с этого же сайта: нормализовать слаги страниц Polylang, чтобы /about/, /ru/about/, /uk/about/ и /es/about/ резолвились одинаково. Пять этапов прошли так:
- Issue: один абзац о несогласованности — агент за минуту собрал issue с указаниями на файлы.
- Анализ: агент проследил логику слагов по Polylang, rewrite-правилам и теме, сохранил всё в
docs/analysis/polylang-slugs.mdс тремя вариантами решения. - План: выбрали наименее рискованный вариант (одноразовый скрипт нормализации при деплое), агент разбил его на маленький набор правок и сам скрипт.
- Реализация: агент написал скрипт, я смотрел каждый diff. Два момента, пойманных на ревью: лишнее переименование и пропущенный language-guard. Оба поправлены до коммита.
- Тест и деплой: Chrome DevTools MCP проверил, что все четыре языковые URL возвращают 200 после прогона скрипта локально. Деплой я сделал руками одной командой:
git pull && wp eval-file && wp rewrite flush.
Полное время: меньше часа на задачу, которая раньше съела бы половину дня. Агент не «придумал решение». Он убрал накладные расходы вокруг него.
FAQ
Нужен ли платный план для серьёзной работы?
Для повседневной работы — да. На бесплатных тарифах можно попробовать процесс, но реальная продуктивность приходит с длинным контекстом и быстрыми моделями. Стоимость мала по сравнению с часом разработчика.
Заменят ли AI-агенты разработчиков?
В нынешнем виде — нет. Они заменяют задачи, а не роль. Узкое место разработки — это решения, проектирование и ответственность, и ничего из этого пока не делегируется. Агенты делают разработчиков быстрее. Это скорее поднимает планку, чем опускает.
Можно ли разрешать агенту выполнять shell-команды?
Да, при двух условиях: ограниченное окружение (контейнер или scoped) и явное подтверждение для всего деструктивного. Никогда не отключайте подтверждения на машине, у которой есть путь до прода.
Claude Code, Codex или Cursor — что выбрать?
Claude Code, Codex, Cursor и Gemini — все заслуживают внимания, но это не один и тот же инструмент. Cursor сильнее всего, когда нужен агент внутри IDE, background agents и PR-review рядом с редактором. Claude Code особенно хорош для terminal-native работы с сильной project memory, settings и hooks. Codex интересен там, где хочется один и тот же agentic workflow в CLI, облаке, IDE и мобильном handoff. Gemini CLI и Gemini Code Assist логичны, если команда уже живёт в Google-экосистеме, а Jules ближе к асинхронному coding agent для задач из GitHub. Правильный ответ всё равно простой: попробовать каждый на реальной задаче, а не на демо.
Какая привычка даёт максимальный эффект?
Чистый CLAUDE.md (или его аналог), который вы поддерживаете в актуальном состоянии. Все остальные улучшения нарастают сверху.
Ключевые выводы
- AI-агент — это быстрый ассистент, а не автономный инженер. Если относиться к нему так, остальная схема собирается сама.
- Безопасность, ограниченные доступы и ручной контроль над деструктивными операциями — без вариантов.
- Главный прирост продуктивности — не в генерации кода, а в исчезновении поддерживающей работы вокруг него.
- Чистый
CLAUDE.md, продуманные MCP-интеграции и процесс из пяти этапов покрывают большую часть пути. - Контекст — это бюджет: начинайте новые сессии чаще, сохраняйте анализ в файлы, узко формулируйте каждый промпт.
- Ответственность за архитектуру, решения и последствия остаётся за разработчиком.
Похожие статьи
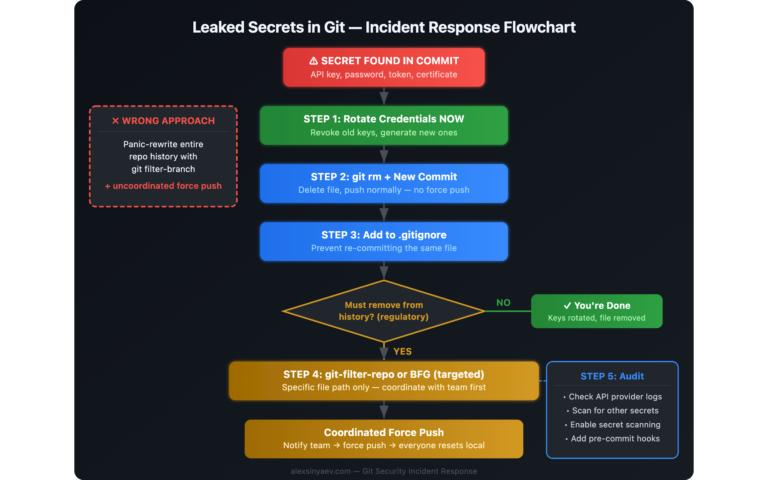
- Когда утечка секрета в Git обернулась переписыванием четырёх лет истории — реальный инцидент, который объясняет правило №1 лучше любого гайда.
- Отладка продакшен-сайта после ИИ-деплоя — что делать, когда задеплоенное агентом ломается в продакшене.
- Как я создал и задеплоил кастомную WordPress-тему с AI-агентами менее чем за 6 часов — тот же процесс на реальном проекте от начала до конца.