La mayoría de artículos sobre agentes de IA o los venden como magia o avisan de que mañana sustituirán a los desarrolladores. Después de usar Claude Code, Codex, Cursor y las herramientas Gemini de Google en proyectos reales, mi visión es más aburrida y, creo, más útil: un agente de IA es un desarrollador junior muy rápido que no se cansa, no capta el contexto y al que nunca hay que dejar solo con acceso a producción. Todo este flujo de trabajo nace de esa única idea.
Esta guía es para desarrolladores que ya superaron el momento «guau, ha escrito una función» y quieren un proceso repetible: reglas, herramientas, plantillas de prompts, etapas y aquello que sigo haciendo a mano.
Actualizado en mayo de 2026: los agentes de IA para desarrollo ya no son solo autocomplete más inteligente. Codex vive en CLI, IDE, nube y flujos móviles, Claude Code tiene un modelo maduro de permisos y hooks, Cursor está empujando background agents y AI review de pull requests, Google está moviendo Gemini CLI, Gemini Code Assist y Jules, y MCP se ha convertido en la capa común de integración. La oportunidad es mayor, pero el coste de equivocarse también.
Por qué la pregunta de la seguridad pesa más que la de la productividad
Un caso ilustrativo. En 2025, The Guardian publicó un incidente en el que un agente de IA borró la base de datos de producción de una empresa por interpretar literalmente una instrucción. No es un bug raro. Es el comportamiento normal de un agente: lee la instrucción y la ejecuta lo más directamente posible, sin entender el contexto de negocio.
Tengo mi propia versión, menos espectacular, de esa historia. Al principio le pedí a un agente que «limpiara los archivos sobrantes del proyecto». Borró sin dudar una carpeta que aún no había commiteado, junto con medio día de trabajo. El agente hizo exactamente lo que le pedí. El error fue mío: la formulación, el scope, el entorno, la falta de confirmación. Cuando interiorizas que ese modo de fallo es estructural y no excepcional, el resto del flujo deja de parecer paranoico y empieza a parecer razonable.
Por eso la pregunta real hoy no es «cómo uso la IA», sino «cómo la uso de forma segura». Una vez aceptado ese encuadre, el resto del flujo de trabajo se vuelve evidente.

Cinco reglas que no rompo
No dependen del modelo ni de la herramienta y aplican igual a Claude Code, Codex, Cursor, Gemini o cualquier cosa que salga mañana.
- Mínimo privilegio, siempre. El agente recibe únicamente las credenciales y permisos necesarios para la tarea actual. Nunca un token de admin «por si acaso». Para GitHub, un token fine-grained acotado a un solo repositorio con los permisos justos. Para la base de datos, un usuario de solo lectura salvo que la escritura sea explícitamente el objetivo. Para la nube, credenciales temporales con caducidad.
- Vigila lo que hace, sobre todo la primera vez. Los CLIs modernos piden confirmación para comandos de shell por defecto. Déjalo activado. El día que lo desactives será el día que algo se rompa.
- Las operaciones destructivas no se delegan. Migraciones de base de datos, borrados, force push, cambios de infraestructura, todo lo que toca dinero o autenticación. Eso lo hago yo. El agente puede preparar el comando y explicar qué hace. El Enter lo pulso yo.
- Los commits y los push se quedan con el desarrollador. El agente puede redactar el mensaje y preparar los archivos. Yo reviso el diff línea a línea antes de
git commit, ygit pushes siempre manual. - Confía en la tarea, no en sus consecuencias.
Si te quedas solo con la última frase, ya es suficiente.
Configuración inicial del proyecto
La mayoría de herramientas funcionan parecido: instalas un CLI (por ejemplo, Claude Code u OpenAI Codex), lo apuntas al repositorio y deja que indexe el proyecto. A partir de ahí, tres elementos de configuración hacen el grueso del trabajo.
Qué cambió en los flujos con agentes de IA hasta mayo de 2026
Las herramientas han pasado de «chat con mi repo» a un pequeño modelo operativo para construir software. El artículo de OpenAI sobre ejecutar Codex de forma segura resume bien el patrón: mantener al agente dentro de límites técnicos, permitir que las acciones de bajo riesgo avancen rápido y hacer explícitas las de alto riesgo. Es el mismo principio que aplico localmente.
En Claude Code, settings y hooks ya permiten codificar reglas del proyecto en lugar de confiar solo en una frase del prompt. Los background agents de Cursor son útiles cuando el trabajo puede ocurrir en una rama remota y revisarse después, pero obligan a cuidar mucho los permisos del repositorio: el agente puede ejecutar comandos automáticamente en un entorno remoto. En Google, el panorama se reparte entre Gemini CLI, Gemini Code Assist dentro del IDE y Jules para tareas de código asíncronas conectadas a GitHub. Las integraciones MCP son potentes para GitHub, pruebas en navegador, logs y documentación, pero cada servidor MCP es también una nueva superficie de capacidad. Trátalo como tratarías una dependencia con credenciales.
Mi regla para 2026 es sencilla: cuanto más autónomo sea el agente, más explícito debe ser el límite. Autonomía sin credenciales acotadas, puertas de revisión y pruebas reproducibles no es productividad. Es velocidad aplicada a la incertidumbre.
1. CLAUDE.md — la memoria a largo plazo del agente
El paso más importante es la inicialización. En Claude Code, /init genera un archivo CLAUDE.md en la raíz del repo. Este archivo se carga en cada conversación. Es donde le cuentas al agente cómo funciona el proyecto de verdad.
Nunca aceptes el archivo generado tal cual. El esqueleto es razonable, pero casi siempre se equivoca en los detalles: inventa comandos, omite convenciones, describe la base de código con un optimismo poco realista. Léelo línea a línea y corrígelo.
Un buen CLAUDE.md responde, en este orden, a:
- Qué es este proyecto, en un párrafo que entienda alguien que llega de fuera.
- Stack y versiones: PHP 8.3, Node 20, la versión exacta del framework, cualquier cosa rara.
- Comandos: cómo se ejecuta, prueba, lintea y despliega. Comandos reales que funcionan hoy, no aspiracionales.
- Arquitectura: dónde vive cada cosa, por qué, cuáles son las capas. Dos o tres párrafos, no una novela.
- Convenciones: nombres, estructura de archivos, lo que corregirías en una PR.
- Zonas prohibidas: archivos y carpetas que no debe tocar, aunque algo cercano «no esté bien».
- Procedimiento de despliegue, especialmente las partes manuales.
Escríbelo como un onboarding para alguien que se incorpora al equipo. El agente lo usa igual.
1b. Un solo AGENTS.md para todos los agentes
Un patrón pequeño que se rentabiliza en cuanto usas más de una herramienta. En lugar de mantener un CLAUDE.md, un GEMINI.md y la configuración de Codex con el mismo contenido, ten un único AGENTS.md en la raíz del repo como fuente de verdad y que cada archivo específico de la herramienta simplemente lo referencie:
# CLAUDE.md
@AGENTS.mdLo mismo para GEMINI.md y cualquier otro agente que soporte referencias a archivos. Editas un solo archivo y todos los agentes recogen el cambio. Se acabó el «actualicé las instrucciones de Claude y olvidé las de Gemini» y la divergencia silenciosa entre herramientas.
2. Ajustes y permisos
Los CLIs modernos permiten separar los comandos en «ejecutar sin preguntar» y «pedir siempre confirmación». Úsalo. Yo permito en silencio los de solo lectura (git status, git diff, ls, cat) y exijo confirmación para todo lo demás. Los cinco segundos de pulsar y son el seguro más barato de tu flujo.
3. Hooks para restricciones duras
Todo lo que deba cumplirse, no solo pedirse en el prompt, va a hooks. Por ejemplo, un pre-commit que bloquee push a main, o un check que prohíba editar ciertos archivos. El agente no puede «olvidarse» de un hook. De una instrucción, sí.
Las herramientas MCP que conecto
MCP (Model Context Protocol) es el estándar que permite a los agentes hablar con sistemas externos. Tres integraciones son fijas en mi setup y unas cuantas las evito a propósito.
GitHub MCP
El servidor oficial de GitHub MCP deja al agente crear issues, leer PRs, comentar, lanzar consultas para revisiones de código y buscar código entre repos. Uso un token fine-grained acotado a un único repositorio con los permisos justos para la tarea. Nunca un token personal con admin de organización. Nunca el mismo token entre proyectos.
Laravel Boost
Para backends en Laravel, Laravel Boost expone rutas, logs, consultas a la base de datos y comandos Artisan al agente. Elimina mucho ida y vuelta del tipo «enséñame dónde se define esta ruta». Lo que más uso es la inspección de rutas: el agente responde a «qué controlador atiende esta URL» sin grep.
Chrome DevTools MCP
Chrome DevTools MCP le da al agente un navegador real. Puede navegar, hacer click, rellenar formularios, mirar el panel de red, leer la consola, hacer capturas y lanzar Lighthouse. Eso es lo que hace posible un testing end-to-end ligero sin montar primero un suite de Playwright.
Lo que deliberadamente no le doy al agente
Credenciales de la base de producción. Cualquier cosa con scope de facturación. Claves SSH a servidores en producción. Mi token personal de GitHub. La regla es simple: si un solo comando equivocado crearía un incidente, el agente no lo recibe.
Mi flujo en cinco etapas
Una vez configurado el agente, cada tarea no trivial pasa por las mismas cinco etapas. El objetivo de la estructura no es burocracia. Es mantener al agente útil donde es rápido y fuera de donde es peligroso.

Etapa 1. Crear el issue
Antes, redactar un buen issue en GitHub me costaba quince minutos. Ahora describo la tarea en un párrafo y dejo que el agente redacte el issue, ponga labels y enlace los relacionados. Ejemplo:
«Crea un issue de GitHub: añadir soporte backend para el bloque Usage Statistics en la página de Subscription para usuarios de la extensión del navegador. Reproduce la implementación que ya existe para SDK. La respuesta debe exponer
wordsLimit,wordsCount,wordsLeft,percentageUsed,percentageLeft. Referencia el controlador del SDK. Propón criterios de aceptación».
El resultado es un issue estructurado con contexto, criterios de aceptación, referencias a archivos y los labels correctos, en menos de un minuto. Lo releo antes de guardar. El truco es cargar el prompt de concreción: nombrar la implementación existente, los campos, la página. Así el agente no inventa detalles.
Etapa 2. Analizar la tarea por escrito
Antes de tocar código, pido al agente que estudie la implementación actual, encuentre los archivos relacionados, identifique restricciones y proponga dos o tres enfoques con sus pros y contras. El paso crítico es pedirle que guarde el resultado como un archivo markdown dentro del repo, por ejemplo docs/analysis/usage-stats.md.
Por qué importa más de lo que parece:
- El agente tiene memoria de trabajo limitada. Un archivo le da contexto persistente que puede recargar sin releer media base de código.
- Mañana lo abres tú y recuerdas la decisión, aunque la conversación original ya no exista.
- Escribirlo obliga al agente a comprometerse con una posición. Las respuestas vagas se vuelven concretas cuando hay que dejarlas por escrito.
- Si el análisis es erróneo, lo cazas ahora, cuando el coste de corregir es un comentario, no un rewrite.
Un prompt que reutilizo:
«Analiza esta tarea antes de escribir nada de código. Lee los archivos relacionados, identifica los puntos donde tiene que aterrizar el cambio, enumera restricciones (forma de los datos, auth, caché, i18n) y propón dos o tres enfoques con sus trade-offs. Guarda el análisis en
docs/analysis/<task-slug>.md. En este paso no edites código de producción».
La frase «no edites código de producción» trabaja de verdad. Sin ella, los agentes tienden a «ir arreglando» mientras analizan.
Un prompt de análisis más fuerte para 2026
«Analiza esta tarea como si prepararas un pequeño implementation RFC. Lee los archivos relevantes, enumera los archivos exactos que inspeccionaste, identifica contratos de datos, límites de permisos, riesgos de cache/i18n y las pruebas que ya cubren comportamiento cercano. Propón dos enfoques: el cambio seguro más pequeño y la solución más limpia a largo plazo. Guarda el resultado en
docs/analysis/<task-slug>.md. No edites código de producción».
La parte de los archivos inspeccionados no es decoración. Hace que el análisis inventado sea más fácil de detectar, porque el agente tiene que mostrar su evidencia.
Etapa 3. Plan y luego implementación
A partir del análisis, el agente produce un plan numerado: qué archivo, qué cambio, en qué orden. En una tarea no trivial, es el momento más barato para detectar suposiciones equivocadas. Corregir un punto del plan es gratis. Rehacer una feature a medias, no.
Muchos CLIs de agente tienen un «plan mode» explícito que bloquea las ediciones hasta que apruebas. Úsalo. Es la diferencia entre discutir un enfoque en 30 segundos y revertir un diff confiadamente equivocado después.
Según el riesgo, ejecuto yo el plan usando al agente como autocompletado avanzado, o dejo que avance paso a paso revisando cada diff. Una regla aproximada:
- Refactors puros, scaffolding, tests, boilerplate: que conduzca el agente, yo reviso el diff en bloque.
- Lógica de negocio nueva: el agente escribe, yo reviso línea a línea.
- Seguridad, auth, pagos, migraciones: escribo yo, el agente revisa.
Etapa 4. Probar en un navegador real
Con Chrome DevTools MCP, el agente puede:
- Abrir el entorno local
- Registrar un usuario de prueba o entrar con una cuenta fixture
- Recorrer el flujo afectado
- Vigilar la consola y el panel de red
- Hacer capturas en el punto de fallo
Funciona bien darle un checklist en el prompt: «abre la página de Subscription, comprueba que el nuevo bloque renderiza, que wordsLeft coincide con la respuesta de la API, que no hay 4xx ni 5xx en la red, haz una captura y reporta».
Lo que esto no detecta: problemas de UX, accesibilidad, pintado lento o interacciones que «funcionan pero se sienten raras». Después del agente paso yo por la feature. La automatización de navegador es una red contra regresiones, no un nivel de calidad.
Etapa 5. PR y commits
Los commits son míos. El agente puede redactar el mensaje, pero yo añado los archivos al stage, reviso el diff y ejecuto el commit. Lo mismo con git push.
La descripción del PR, en cambio, es un excelente objetivo para delegar. Un prompt que da resultados consistentes:
«Escribe una descripción de PR para la rama actual. Incluye: un párrafo de resumen, lista de cambios visibles para el usuario, plan de pruebas, notas de migración o rollout y el enlace al issue. Lee el diff contra
main, no inventes cambios que no estén en el diff».
«No inventes» trabaja en serio. Sin esa cláusula, los agentes rellenan descripciones con cambios verosímiles que no están realmente en el código.
Dónde aparece el ahorro real
Si lo mides honestamente, el agente casi nunca ahorra tiempo «escribiendo el código». El código es una parte pequeña del trabajo. El ahorro está alrededor:
- Crear el issue: de 15 minutos a aproximadamente 1.
- Análisis sobre código desconocido: de horas de lectura a 5–10 minutos de salida estructurada.
- Descripción del PR: de 10–15 minutos a 1.
- Pruebas básicas de regresión: un buen trozo de clicks repetitivos desaparece.
- Boilerplate (CRUD, formularios, fixtures, migraciones repetitivas): minutos en lugar de decenas de minutos.
- Leer documentación para encontrar un detalle: el agente lee, tú preguntas. Este ahorro discreto gana al resto.
Ese es el valor real: el agente elimina el trabajo de soporte que rodea la ingeniería, y queda más día para las decisiones que solo debería tomar una persona. El ahorro de una hora al día es real. La promesa «el agente me lo construyó» es mayoritariamente marketing.
El checklist que uso antes de darle una tarea a un agente
- ¿Puedo describir el resultado esperado en un párrafo? Si no, primero aclaro la tarea yo.
- ¿El blast radius es pequeño? Un ajuste CSS, una fixture de test o un script local son buenos candidatos. Payments, auth y migrations no.
- ¿El agente tiene solo el acceso que necesita? Solo lectura por defecto, escritura únicamente donde la tarea lo exige.
- ¿Hay una forma de verificar el resultado? Un test, un recorrido en navegador, un comando WP-CLI, una captura, revisión del diff.
- ¿Puedo tirar el intento a la basura? Si la respuesta es no, uso una rama, un worktree, o hago el trabajo manualmente.
El checklist es aburrido a propósito. El proceso aburrido es lo que permite usar herramientas interesantes sin convertir producción en el experimento.
Lecciones no obvias que aprendí a las malas
La degradación del contexto es real
Cuanto más larga es la conversación, peor funciona el agente. Tras una sesión larga de ediciones, desvíos e intentos fallidos, el modelo empieza a contradecir decisiones previas, a olvidar restricciones del system prompt y a reintroducir bugs que ya había corregido. Cuando lo notas, no insistas. El movimiento correcto es abrir una conversación nueva, apuntar al archivo de análisis de la etapa 2 y continuar desde ahí. Es uno de los hábitos de mayor impacto al trabajar con agentes.
Los agentes se exceden cuando la tarea es vaga
Pide «un fix» y obtendrás el fix más un rename, más una «limpieza menor», más un refactor de una función que el agente consideró fea. Establece siempre el límite de forma explícita: «cambia solo la función X. No refactorices nada más. No renombres. No muevas archivos». Suena obsesivo hasta que has pasado una hora revirtiendo cambios no relacionados.
Escribe tests con el agente, pero no para el agente
Dejar que el agente escriba el test de la feature que acaba de escribir es una trampa clásica. El test acaba codificando su propio malentendido en lugar del requisito. O escribes el test tú primero y dejas que el agente lo ponga en verde, o escribes el test en una conversación separada. El segundo modelo discute mejor que el mismo modelo.
Usa git worktrees para trabajo paralelo del agente
Cuando quieras dejar al agente intentar algo arriesgado sin bloquear tu rama principal, ejecuta en un git worktree aparte. Es un directorio aislado en otra rama, y puedes descartarlo entero si la cosa va mal. Mucho más seguro que stash y cambiar de rama bajo un agente que quizá no entienda el cambio de contexto.
El coste real no son los tokens, es tu atención
La gente se preocupa por los tokens. En un plan de pago serio, el coste marginal por tarea es pequeño comparado con una hora de desarrollador. El presupuesto real es tu atención. Las revisiones y aprobaciones son el recurso escaso, no los tokens. Eso cambia qué optimizaciones merecen la pena.
Dos agentes revisando ganan a uno solo, pero no tanto como crees
Un patrón que está creciendo es usar dos agentes a la vez. Uno genera la solución, el otro la revisa. Claude implementa, ChatGPT revisa, o al revés. Funciona sorprendentemente bien: un segundo modelo ve puntos ciegos del primero. Pero no es una bala de plata. Dos agentes pueden coincidir con total seguridad en la misma respuesta equivocada, sobre todo cuando les falta contexto específico del proyecto. La decisión final sigue siendo humana.
La trampa de la confianza
Los agentes casi nunca suenan inseguros. Explicarán un enfoque que no funciona con la misma autoridad tranquila que uno que sí. La pregunta útil rara vez es «¿esto está bien?» (la respuesta será que sí). Es «¿qué tendría que ser cierto para que esto fallara y cómo lo compruebo?».
Errores típicos de quien empieza
- Dar al agente credenciales de admin. Reduce siempre el scope. Un token de solo lectura cubre el 80% de los casos.
- Saltarse la revisión del
CLAUDE.md. Basura entra, basura sale, en todas las tareas siguientes. - Aceptar código sin leer el diff. El agente borrará tests con tal de que «pasen», o comentará asserts que fallan.
- Dejar al agente ejecutar
git pusho comandos contra producción. El riesgo no compensa la pulsación ahorrada. - Pedir «un fix» sin etapa de análisis. Obtendrás código verosímil que ataca el síntoma, no la causa.
- Estirar una sola conversación durante horas. Empieza de nuevo. El coste de re-primar el contexto es mucho menor que el de actuar sobre contexto degradado.
- Creerse los autoinformes del agente. «Todos los tests pasan» merece una verificación. «Está totalmente implementado» también.
Un ejemplo concreto de mi propio flujo
Una tarea reciente en esta misma web: normalizar los slugs de páginas de Polylang para que /about/, /ru/about/, /uk/about/ y /es/about/ resolvieran igual. Las cinco etapas fueron así:
- Issue: un párrafo describiendo la inconsistencia, el agente redactó el issue con punteros a archivos en aproximadamente un minuto.
- Análisis: el agente rastreó la lógica de slugs en Polylang, las reglas de rewrite y el theme, y guardó el resultado en
docs/analysis/polylang-slugs.mdcon tres enfoques candidatos. - Plan: elegimos la opción de menor riesgo (un script de normalización ejecutado una vez en el despliegue) y el agente lo desglosó en un conjunto pequeño de cambios más el script.
- Implementación: el agente escribió el script, yo revisé cada diff. Dos problemas detectados en la revisión: un rename de más y una falta de guard por idioma. Ambos corregidos antes del commit.
- Pruebas y despliegue: Chrome DevTools MCP verificó que las cuatro URLs de idioma respondían 200 tras ejecutar el script en local. Desplegué a mano con una línea:
git pull && wp eval-file && wp rewrite flush.
Tiempo total: menos de una hora para un cambio que antes habría llevado una tarde. El agente no inventó la solución. Eliminó el coste de buscar y leer alrededor.
FAQ
¿Necesito un plan de pago para sacarles partido?
Para uso serio diario, sí. Los planes gratuitos sirven para probar el flujo, pero la productividad real llega con ventanas de contexto largas y modelos rápidos. El coste es pequeño comparado con una hora de desarrollador.
¿Los agentes de IA van a sustituir a los desarrolladores?
Tal como están hoy, no. Sustituyen tareas, no roles. El cuello de botella del software sigue siendo el criterio, el diseño y la responsabilidad, y nada de eso es delegable todavía. Los agentes hacen más rápidos a los desarrolladores. Eso tiende a subir el listón, no a bajarlo.
¿Es seguro dejar al agente ejecutar comandos de shell?
Sí, con dos condiciones: un entorno acotado (contenedor o con scope) y confirmación explícita para cualquier acción destructiva. Nunca desactives las confirmaciones en una máquina que pueda llegar a producción.
Claude Code, Codex o Cursor, ¿cuál elijo?
Claude Code, Codex, Cursor y Gemini merecen atención, pero no son intercambiables. Cursor brilla cuando quieres el agente dentro del IDE, con background agents y PR review cerca del editor. Claude Code es especialmente fuerte para trabajo terminal-native con buena project memory, settings y hooks. Codex resulta interesante cuando quieres el mismo agentic workflow en CLI, nube, IDE y handoff móvil. Gemini CLI y Gemini Code Assist tienen sentido si tu equipo ya vive en el ecosistema de Google, mientras Jules se parece más a un coding agent asíncrono para tareas desde GitHub. La respuesta correcta sigue siendo probar cada uno en una tarea real, no en una demo.
¿Cuál es el hábito de mayor impacto?
Mantener un CLAUDE.md (o equivalente) limpio y actualizado. Todas las demás mejoras se acumulan sobre eso.
Puntos clave
- Un agente de IA es un asistente rápido, no un ingeniero autónomo. Si lo tratas así, el resto del flujo cae por su propio peso.
- Seguridad, credenciales con scope reducido y control humano sobre las acciones destructivas son innegociables.
- El mayor salto de productividad no es generar código, es eliminar el trabajo de soporte alrededor.
- Un
CLAUDE.mdlimpio, una configuración MCP cuidada y un flujo en cinco etapas cubren la mayor parte del camino. - Trata el contexto como un presupuesto real: abre sesiones nuevas con frecuencia, guarda el análisis en archivos y acota cada prompt.
- La responsabilidad sobre la arquitectura, las decisiones y las consecuencias se queda con el desarrollador.
Artículos relacionados
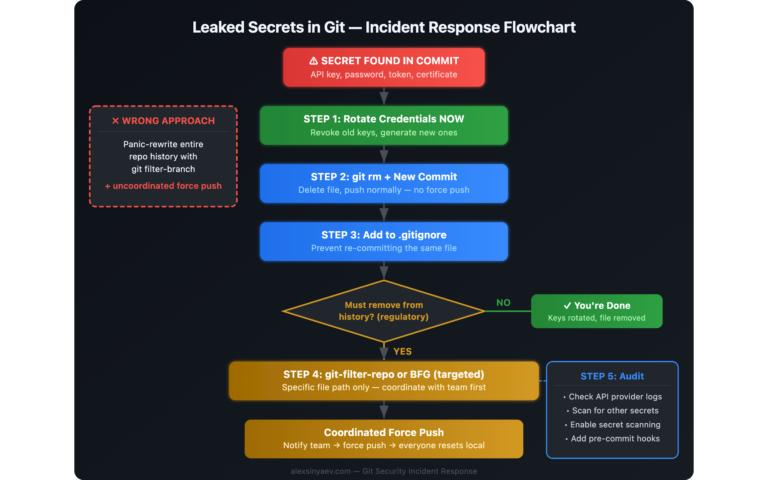
- Cuando un secreto filtrado en Git acabó reescribiendo cuatro años de historial — un incidente real que explica la regla nº1 mejor que cualquier guía.
- Depuración de un sitio en producción tras despliegue con IA — qué hacer cuando lo que despliega el agente se rompe en producción.
- Cómo construí y desplegué un tema de WordPress personalizado con agentes de IA en menos de 6 horas — el mismo flujo aplicado de principio a fin en un proyecto real.